mirror of
https://github.com/RYDE-WORK/MiniCPM.git
synced 2026-01-19 21:03:39 +08:00
12 KiB
12 KiB
MiniCPM
Hugging Face | ModelScope | WiseModel | 技术报告
Quick Links
- Downloading
- Quick Start
- Benchmark
- Deployment on Mobile Phones
- Demo & API
- Fine-tuning Models
- LICENSE
- Citation
- Show Cases
Downloading
| HuggingFace | ModelScope | WiseModel |
|---|---|---|
| sft-bf16 | sft-bf16 | sft-bf16 |
| sft-fp32 | sft-fp32 | sft-fp32 |
| dpo-bf16 | dpo-bf16 | dpo-bf16 |
| dpo-fp16 | dpo-fp16 | dpo-fp16 |
| dpo-fp32 | dpo-fp32 | dpo-fp32 |
Quick Start
vLLM
- Install vLLM supporting MiniCPM.
- MiniCPM adopts the MUP structure, and this structure introduces some extra scaling operations to make the training process stable. And the MUP structure is little different from the structure used by Llama and other LLMs.
- vLLM 0.2.2 is adapted to MiniCPM in the folder inference. More vLLM versions will be supported in the future.
pip install inference/vllm
- Transfer Huggingface Transformers repo to vLLM-MiniCPM repo, where
<hf_repo_path>,<vllmcpm_repo_path>are local paths.
python inference/convert_hf_to_vllmcpm.py --load <hf_repo_path> --save <vllmcpm_repo_path>
- Examples
cd inference/vllm/examples/infer_cpm
python inference.py --model_path <vllmcpm_repo_path> --prompt_path prompts/prompt_final.txt
Huggingface
- Install
transformers>=4.36.0andaccelerate,run the following python code.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM-2B-dpo-bf16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "Which city is the capital of China?", temperature=0.8, top_p=0.8)
print(responds)
- Examples
The capital city of China is Beijing. Beijing is not only the political center of China but also a cultural and economic hub. It is known for its rich history and numerous landmarks, such as the Great Wall, the Forbidden City, and the Temple of Heaven. The city is also home to the National Stadium, also known as the "Bird's Nest," and the National Aquatics Center, or "Water Cube." Beijing is a significant city in China, with a population of over 21 million people.
Benchmark
| HuggingFace | ModelScope | WiseModel |
|---|---|---|
| sft-bf16 | sft-bf16 | sft-bf16 |
| sft-fp32 | sft-fp32 | sft-fp32 |
| dpo-bf16 | dpo-bf16 | dpo-bf16 |
| dpo-fp16 | dpo-fp16 | dpo-fp16 |
| dpo-fp32 | dpo-fp32 | dpo-fp32 |
Multi-modal
| Models | MME(P) | MMB-dev(en) | MMB-dev(zh) | MMMU-val | CMMMU-val |
|---|---|---|---|---|---|
| LLaVA-Phi | 1335.1 | 59.8 | / | / | / |
| MobileVLM | 1288.9 | 59.6 | / | / | / |
| Imp-v1 | 1434.0 | 66.5 | / | / | / |
| Qwen-VL-Chat | 1487 | 60.6 | 56.7 | 35.9 | 30.7 |
| MiniCPM-V | 1446 | 67.3 | 61.9 | 34.7 | 32.1 |
DPO
| Models | MT-bench |
|---|---|
| GPT-4-turbo | 9.32 |
| GPT-3.5-turbo | 8.39 |
| Mistral-8*7b-Instruct-v0.1 | 8.30 |
| Claude-2.1 | 8.18 |
| Zephyr-7B-beta | 7.34 |
| MiniCPM-2B | 7.25 |
| Vicuna-33B | 7.12 |
| Zephyr-7B-alpha | 6.88 |
| LLaMA-2-70B-chat | 6.86 |
| Mistral-7B-Instruct-v0.1 | 6.84 |
| LLaMA-2-13B-chat | 6.65 |
| Vicuna-13B | 6.57 |
| MPT-34B-instruct | 6.39 |
| LLaMA-2-7B-chat | 6.27 |
| Vicuna-7B | 6.17 |
| MPT-7B-chat | 5.42 |
Deployment on mobile phones
Tutorial
- After INT4 quantization, MiniCPM only occupies 2GB of space, meeting the requirements of inference on end devices.
- We have made different adaptations for different operating systems.
- Note: The current open-source framework is still improving its support for mobile phones, and not all chips and operating system versions can successfully run MLC-LLM or LLMFarm.
- Android, Harmony OS
- Adapt based on MLC-LLM.
- Adapted for text model MiniCPM, and multimodel model MiniCPM-V.
- Support MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4、MiniCPM-V.
- Compile and Installation Guide
- iOS
- Adapt based on LLMFarm.
- Adapted for text model MiniCPM.
- Support MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4.
- Compile and Installation Guide
Performance
- We did not conduct in-depth optimization and system testing on the mobile inference model, only verifying the feasibility of MiniCPM using mobile phone chips for inference.
- There have been no previous attempts to deploy multimodal models on mobile phones. We have verified the feasibility of deploying MiniCPM-V on mobile phones based on MLC-LLM this time, and it can input and output normally. However, there also exist a problem of long image processing time, which needs further optimization :)
- We welcome more developers to continuously improve the inference performance of LLMs on mobile phones and update the test results below.
| Mobile Phones | OS | Processor | Memory(GB) | Inference Throughput(token/s) |
|---|---|---|---|---|
| OPPO Find N3 | Android 13 | snapdragon 8 Gen2 | 12 | 6.5 |
| Samsung S23 Ultra | Android 14 | snapdragon 8 Gen2 | 12 | 6.4 |
| Meizu M182Q | Android 11 | snapdragon 888Plus | 8 | 3.7 |
| Xiaomi 12 Pro | Android 13 | snapdragon 8 Gen1 | 8+3 | 3.7 |
| Xiaomi Redmi K40 | Android 11 | snapdragon 870 | 8 | 3.5 |
| Oneplus LE 2100 | Android 13 | snapdragon 870 | 12 | 3.5 |
| Oneplus HD1900 | Android 11 | snapdragon 865 | 8 | 3.2 |
| Oneplus HD1900 | Android 11 | snapdragon 855 | 8 | 3.0 |
| Oneplus HD1905 | Android 10 | snapdragon 855 | 8 | 3.0 |
| Oneplus HD1900 | Android 11 | snapdragon 855 | 8 | 3.0 |
| Xiaomi MI 8 | Android 9 | snapdragon 845 | 6 | 2.3 |
| Huawei Nova 11SE | Harmony 4.0.0 | snapdragon 778 | 12 | 1.9 |
| Xiaomi MIX 2 | Android 9 | snapdragon 835 | 6 | 1.3 |
| iPhone 15 Pro | iOS 17.2.1 | A16 | 8 | 18.0 |
| iPhone 15 | iOS 17.2.1 | A16 | 6 | 15.0 |
| iPhone 12 Pro | iOS 16.5.1 | A14 | 6 | 5.8 |
| iPhone 12 | iOS 17.2.1 | A14 | 4 | 5.8 |
| iPhone 11 | iOS 16.6 | A13 | 4 | 4.6 |

Demo & API
Web-demo based on Gradio
Using the following command can launch the gradio-based demo.
python demo/gradio_based_demo.py
Fine-tuning
-
Parameter-efficient Tuning
- With parameter-efficient tuning, we can tune MiniCPM using one piece of NVIDIA GeForce GTX 1080/2080.
- Code for Parameter-efficient Tuning
-
Full-parameter Tuning
- Using BMTrain,as well as checkpointing and ZeRO-3 (zero redundancy optimizer),we can tune all parameters of MiniCPM using one piece of NVIDIA GeForce GTX 3090/4090.
- This code will be available soon.
LICENSE
Model LICENSE
- This repository is released under the Apache-2.0 License.
- The usage of MiniCPM model weights must strictly follow the General Model License (GML).
- The models and weights of MiniCPM are completely free for academic research.
- If you intend to utilize the model for commercial purposes, please reach out to cpm@modelbest.cn to obtain the certificate of authorization.
Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
Citation
- Please cite our techinical report if you find our work valuable.
@inproceedings{minicpm2024,
title={MiniCPM:Unveiling the Potential of End-side Large Language Models},
booktitle={OpenBMB Blog},
year={2024}
}
Show Cases
Code
Case 1:

Case 2:

Reasoning
Case 1:

Case 2:
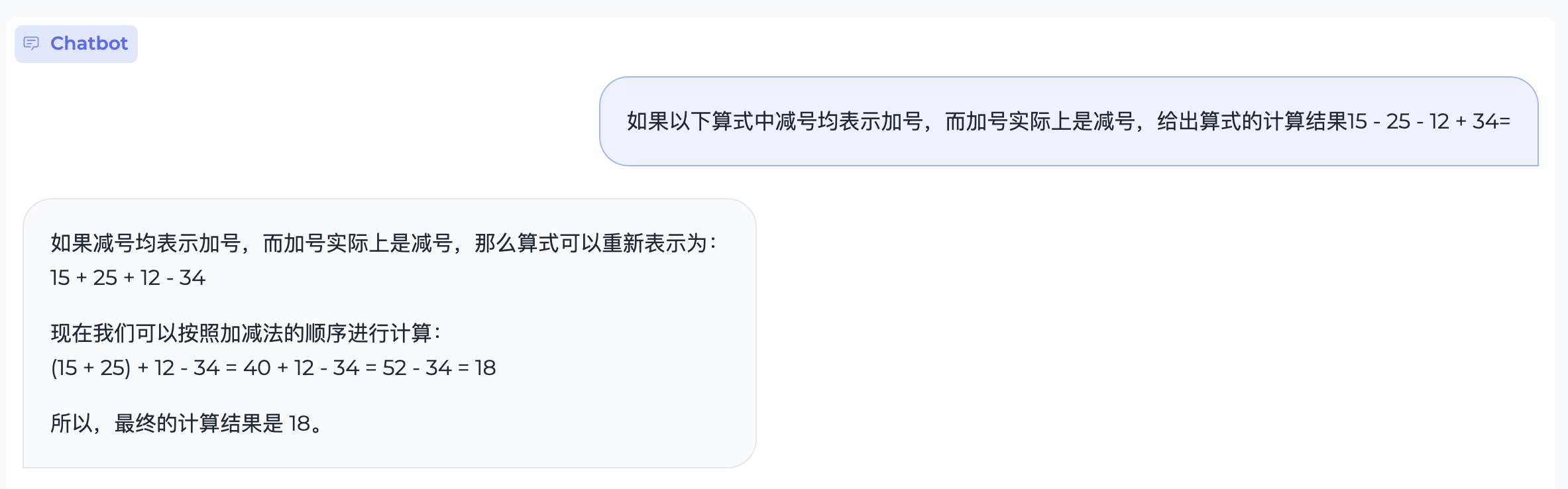
World-Knowledge
Case 1:
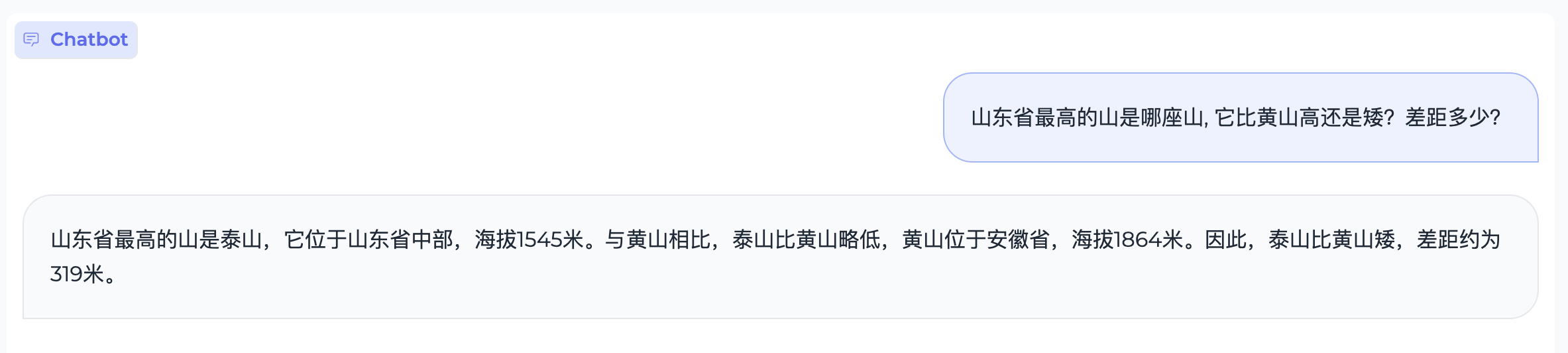
Content Creation
Case 1:
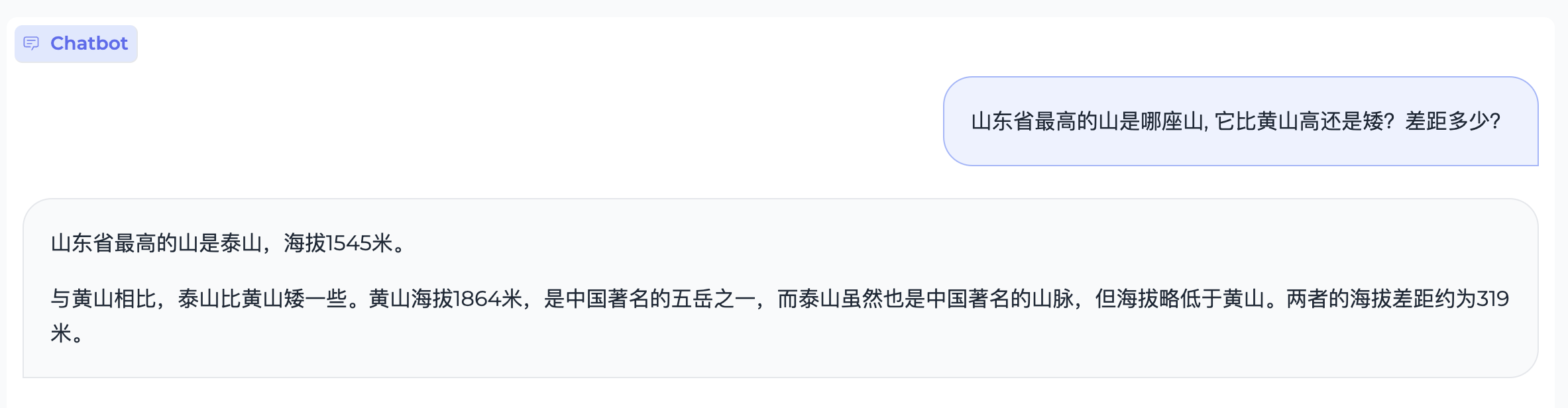
Translation
Case 1:
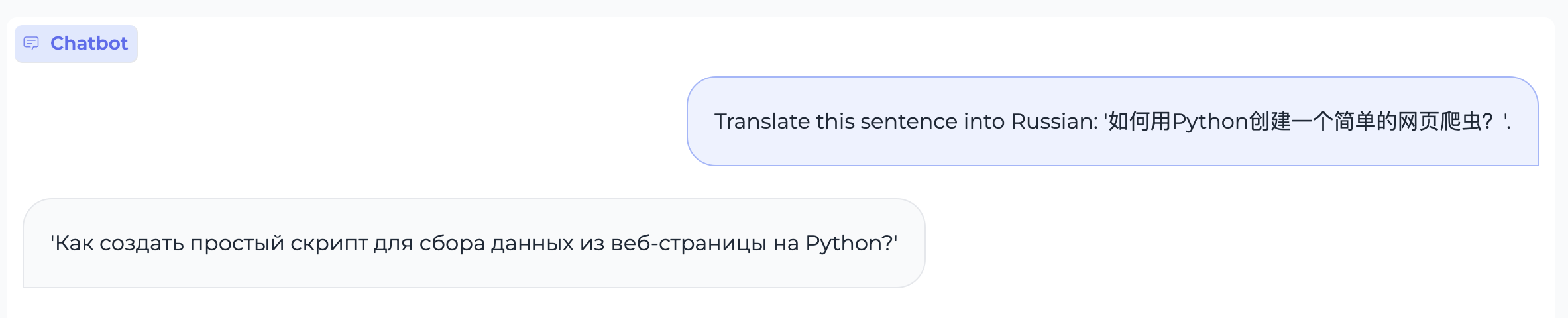
Case 2:
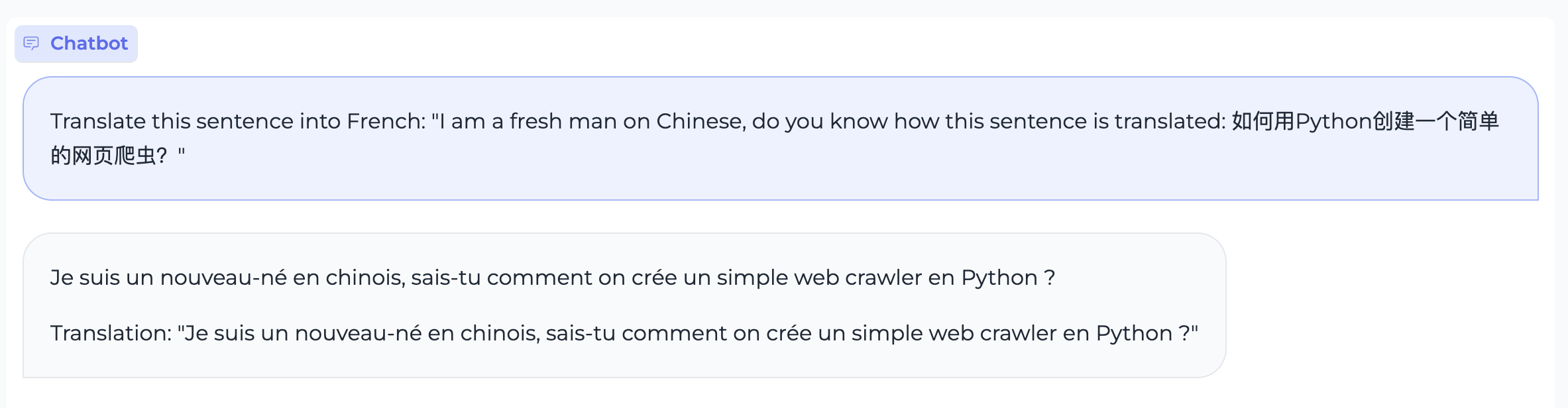
Instruction Following
Case 1:

Case 2:
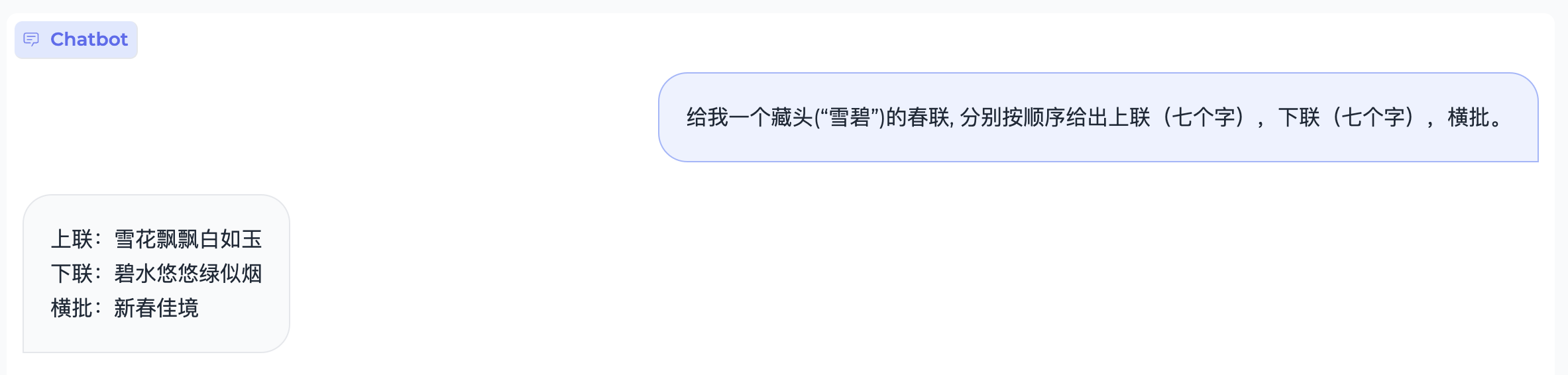
Special characters
Case 1:

Case 2:
