19 KiB
🎉 介绍
KTransformers(发音为 Quick Transformers)旨在通过先进的内核优化和放置/并行策略来增强您对 🤗 [Transformers](https://github.com/huggingface/transformers) 的体验。KTransformers 是一个以 Python 为中心的灵活框架,其核心是可扩展性。通过用一行代码实现并注入优化模块,用户可以获得与 Transformers 兼容的接口、符合 OpenAI 和 Ollama 的 RESTful API,甚至是一个简化的类似 ChatGPT 的 Web 界面。
我们对 KTransformers 的愿景是成为一个用于实验创新 LLM 推理优化的灵活平台。如果您需要任何其他功能,请告诉我们。
🔥 更新
- 2025 年 2 月 10 日:支持 Deepseek-R1 和 V3 在单个(24GB VRAM)/多 GPU 和 382G DRAM 上运行,速度提升高达 3~28 倍。详细教程请参见 这里。
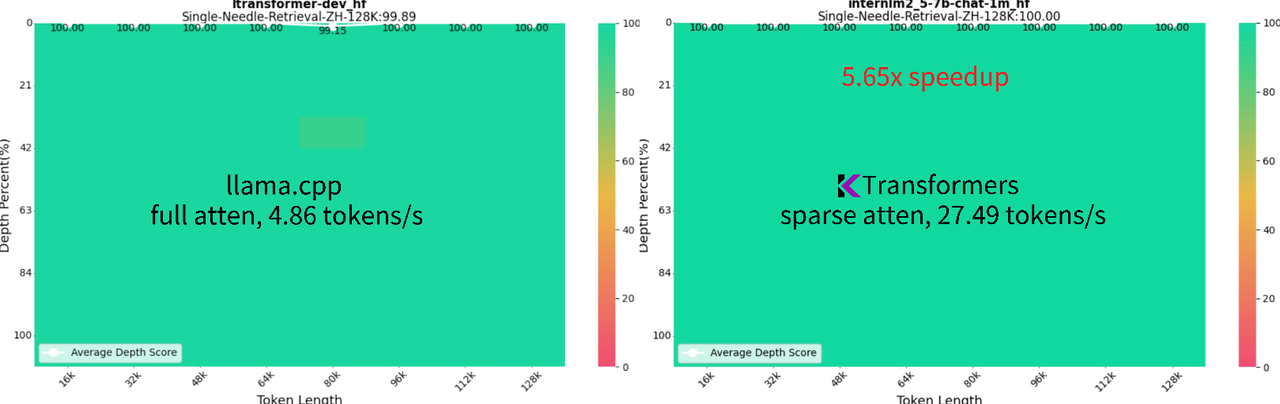
- 2024 年 8 月 28 日:支持 InternLM2.5-7B-Chat-1M 模型下的 1M 上下文,使用 24GB 的 VRAM 和 150GB 的 DRAM。详细教程请参见 这里。
- 2024 年 8 月 28 日:将 DeepseekV2 所需的 VRAM 从 21G 降低到 11G。
- 2024 年 8 月 15 日:更新了详细的 教程,介绍注入和多 GPU 的使用。
- 2024 年 8 月 14 日:支持 llamfile 作为线性后端。
- 2024 年 8 月 12 日:支持多 GPU;支持新模型:mixtral 8*7B 和 8*22B;支持 q2k、q3k、q5k 在 GPU 上的去量化。
- 2024 年 8 月 9 日:支持 Windows。
🌟 案例展示
在仅 24GB VRAM 的桌面上运行 GPT-4/o1 级别的本地 VSCode Copilot
https://github.com/user-attachments/assets/ebd70bfa-b2c1-4abb-ae3b-296ed38aa285
-
[NEW!!!] 本地 671B DeepSeek-Coder-V3/R1:使用其 Q4_K_M 版本,仅需 14GB VRAM 和 382GB DRAM 即可运行(教程请参见 这里)。
- 预填充速度(tokens/s):
- KTransformers:54.21(32 核)→ 74.362(双插槽,2×32 核)→ 255.26(优化的 AMX 基 MoE 内核,仅 V0.3)→ 286.55(选择性使用 6 个专家,仅 V0.3)
- 与 llama.cpp 在 2×32 核下相比,达到 27.79× 速度提升。
- 解码速度(tokens/s):
- KTransformers:8.73(32 核)→ 11.26(双插槽,2×32 核)→ 13.69(选择性使用 6 个专家,仅 V0.3)
- 与 llama.cpp 在 2×32 核下相比,达到 3.03× 速度提升。
- 即将开源发布:
- AMX 优化和选择性专家激活将在 V0.3 中开源。
- 目前仅在预览二进制分发中可用,可从 这里 下载。
- 预填充速度(tokens/s):
-
本地 236B DeepSeek-Coder-V2:使用其 Q4_K_M 版本,仅需 21GB VRAM 和 136GB DRAM 即可运行,甚至在 BigCodeBench 中得分超过 GPT4-0613。
- 更快的速度:通过 MoE 卸载和注入来自 Llamafile 和 Marlin 的高级内核,实现了 2K 提示预填充 126 tokens/s 和生成 13.6 tokens/s 的速度。
- VSCode 集成:封装成符合 OpenAI 和 Ollama 的 API,可无缝集成到 Tabby 和其他前端的后端。
https://github.com/user-attachments/assets/4c6a8a38-05aa-497d-8eb1-3a5b3918429c
在仅 24GB VRAM 的桌面上进行 1M 上下文本地推理
https://github.com/user-attachments/assets/a865e5e4-bca3-401e-94b8-af3c080e6c12
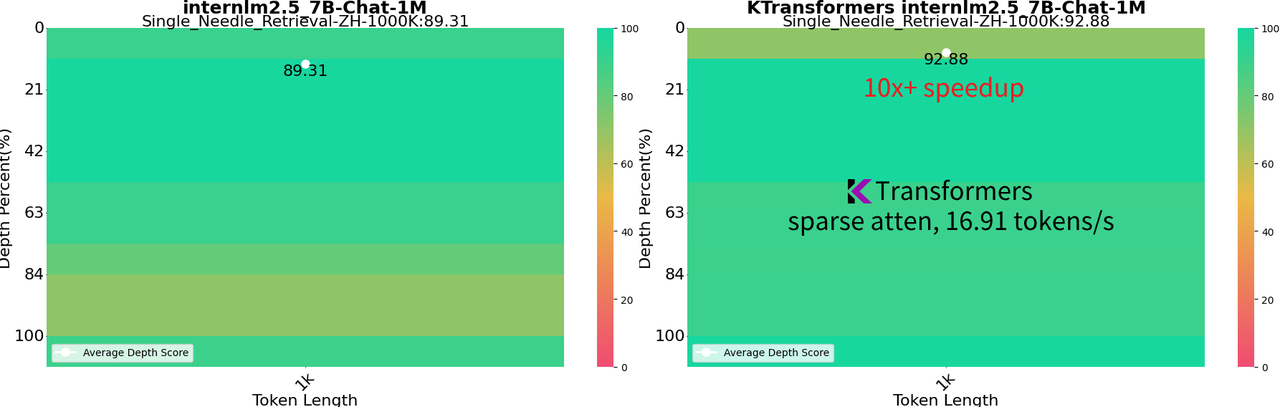
- 1M 上下文 InternLM 2.5 7B:以全 bf16 精度运行,使用 24GB VRAM 和 150GB DRAM,可在本地桌面设置中实现。在 1M "针在干草堆中" 测试中达到 92.88% 的成功率,在 128K NIAH 测试中达到 100%。
-
增强的速度:使用稀疏注意力,通过 llamafile 内核实现 1M 上下文生成 16.91 tokens/s 的速度。这种方法比 llama.cpp 的全注意力方法快 10 倍以上。
-
灵活的稀疏注意力框架:提供了一个灵活的块稀疏注意力框架,用于 CPU 卸载解码。与 SnapKV、Quest 和 InfLLm 兼容。更多信息请参见 这里。
更多高级功能即将推出,敬请期待!
🚀 快速入门
准备工作
一些准备工作:-
如果您还没有 CUDA 12.1 及以上版本,可以从 这里 安装。
# Adding CUDA to PATH export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH export CUDA_PATH=/usr/local/cuda -
Linux-x86_64 系统,需要安装 gcc、g++ 和 cmake
sudo apt-get update sudo apt-get install gcc g++ cmake ninja-build -
我们建议使用 Conda 创建一个 Python=3.11 的虚拟环境来运行我们的程序。
conda create --name ktransformers python=3.11 conda activate ktransformers # 您可能需要先运行 ‘conda init’ 并重新打开 shell -
确保安装了 PyTorch、packaging、ninja
pip install torch packaging ninja cpufeature numpy
安装
-
使用 Docker 镜像,详见 Docker 文档
-
您可以使用 Pypi 安装(适用于 Linux):
pip install ktransformers --no-build-isolation对于 Windows,我们提供了一个预编译的 whl 包 ktransformers-0.2.0+cu125torch24avx2-cp312-cp312-win_amd64.whl,需要 cuda-12.5、torch-2.4、python-3.11,更多预编译包正在制作中。
-
或者您可以下载源代码并编译:
-
init source code
git clone https://github.com/kvcache-ai/ktransformers.git cd ktransformers git submodule init git submodule update -
[可选] 如果您想运行网站,请在执行
bash install.sh之前, 进行 compile the website -
编译并安装(适用于 Linux)
bash install.sh -
编译并安装(适用于 Windows)
install.bat
-
-
如果您是开发者,可以使用 makefile 来编译和格式化代码。makefile 的详细用法请参见 这里
本地聊天
我们提供了一个简单的命令行本地聊天 Python 脚本,您可以运行它进行测试。请注意,这只是一个非常简单的测试工具,仅支持一轮聊天,不记忆上一次输入。如果您想体验模型的全部功能,可以前往 RESTful API 和 Web UI。这里以 DeepSeek-V2-Lite-Chat-GGUF 模型为例,但我们也支持其他模型,您可以替换为您想要测试的任何模型。
运行示例
# 从克隆的仓库根目录开始!
# 从克隆的仓库根目录开始!!
# 从克隆的仓库根目录开始!!!
# 从 Hugging Face 下载 mzwing/DeepSeek-V2-Lite-Chat-GGUF
mkdir DeepSeek-V2-Lite-Chat-GGUF
cd DeepSeek-V2-Lite-Chat-GGUF
wget https://huggingface.co/mzwing/DeepSeek-V2-Lite-Chat-GGUF/resolve/main/DeepSeek-V2-Lite-Chat.Q4_K_M.gguf -O DeepSeek-V2-Lite-Chat.Q4_K_M.gguf
cd .. # 返回仓库根目录
# 启动本地聊天
python -m ktransformers.local_chat --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
# 如果遇到报错 “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, 请尝试:
# GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
# python ktransformers.local_chat --model_path ./DeepSeek-V2-Lite --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
它具有以下参数:
-
--model_path(required): 模型名称 (例如 "deepseek-ai/DeepSeek-V2-Lite-Chat" 将自动从 Hugging Face 下载配置)。或者,如果您已经有本地文件,可以直接使用该路径来初始化模型。Note: .safetensors 文件不是必需的。我们只需要配置文件来构建模型和分词器。
-
--gguf_path(required): 包含 GGUF 文件的目录路径,可以从 Hugging Face 下载。请注意,该目录应仅包含当前模型的 GGUF,这意味着您需要为每个模型使用一个单独的目录。 -
--optimize_rule_path(必需,Qwen2Moe 和 DeepSeek-V2 除外): 包含优化规则的 YAML 文件路径。在 ktransformers/optimize/optimize_rules 目录中有两个预写的规则文件,用于优化 DeepSeek-V2 和 Qwen2-57B-A14,这两个是 SOTA MoE 模型。 -
--max_new_tokens: Int (default=1000). 要生成的最大 new tokens。 -
--cpu_infer: Int (default=10). 用于推理的 CPU 数量。理想情况下应设置为(总核心数 - 2)。
建议模型
| Model Name | Model Size | VRAM | Minimum DRAM | Recommended DRAM |
|---|---|---|---|---|
| DeepSeek-R1-q4_k_m | 377G | 14G | 382G | 512G |
| DeepSeek-V3-q4_k_m | 377G | 14G | 382G | 512G |
| DeepSeek-V2-q4_k_m | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-q4_k_m | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-IQ4_XS | 117G | 10G | 107G | 128G |
| Qwen2-57B-A14B-Instruct-q4_k_m | 33G | 8G | 34G | 64G |
| DeepSeek-V2-Lite-q4_k_m | 9.7G | 3G | 13G | 16G |
| Mixtral-8x7B-q4_k_m | 25G | 1.6G | 51G | 64G |
| Mixtral-8x22B-q4_k_m | 80G | 4G | 86.1G | 96G |
| InternLM2.5-7B-Chat-1M | 15.5G | 15.5G | 8G(32K context) | 150G (1M context) |
更多即将推出。请告诉我们您最感兴趣的模型。
请注意,在使用 DeepSeek 和 QWen 时,需要遵守相应的模型许可证。
点击显示如何运行其他示例
-
Qwen2-57B
pip install flash_attn # For Qwen2 mkdir Qwen2-57B-GGUF && cd Qwen2-57B-GGUF wget https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/qwen2-57b-a14b-instruct-q4_k_m.gguf?download=true -O qwen2-57b-a14b-instruct-q4_k_m.gguf cd .. python -m ktransformers.local_chat --model_name Qwen/Qwen2-57B-A14B-Instruct --gguf_path ./Qwen2-57B-GGUF # 如果遇到报错 “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, 请尝试: # GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct # python ktransformers/local_chat.py --model_path ./Qwen2-57B-A14B-Instruct --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF -
DeepseekV2
mkdir DeepSeek-V2-Chat-0628-GGUF && cd DeepSeek-V2-Chat-0628-GGUF # Download weights wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00001-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00001-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00002-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00002-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00003-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00003-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00004-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00004-of-00004.gguf cd .. python -m ktransformers.local_chat --model_name deepseek-ai/DeepSeek-V2-Chat-0628 --gguf_path ./DeepSeek-V2-Chat-0628-GGUF # 如果遇到报错 “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, 请尝试: # GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat-0628 # python -m ktransformers.local_chat --model_path ./DeepSeek-V2-Chat-0628 --gguf_path ./DeepSeek-V2-Chat-0628-GGUF
| model name | weights download link |
|---|---|
| Qwen2-57B | Qwen2-57B-A14B-gguf-Q4K-M |
| DeepseekV2-coder | DeepSeek-Coder-V2-Instruct-gguf-Q4K-M |
| DeepseekV2-chat | DeepSeek-V2-Chat-gguf-Q4K-M |
| DeepseekV2-lite | DeepSeek-V2-Lite-Chat-GGUF-Q4K-M |
RESTful API and Web UI
Start without website:
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002
Start with website:
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002 --web True
或者,如果您想使用 transformers 启动服务,model_path 应该包含 safetensors 文件:
ktransformers --type transformers --model_path /mnt/data/model/Qwen2-0.5B-Instruct --port 10002 --web True
通过 http://localhost:10002/web/index.html#/chat 访问:
关于 RESTful API 服务器的更多信息可以在这里找到 这里。您还可以在这里找到与 Tabby 集成的示例 这里。
📃 简要注入教程
KTransformers 的核心是一个用户友好的、基于模板的注入框架。这使得研究人员可以轻松地将原始 torch 模块替换为优化的变体。它还简化了多种优化的组合过程,允许探索它们的协同效应。
鉴于 vLLM 已经是一个用于大规模部署优化的优秀框架,KTransformers 特别关注受资源限制的本地部署。我们特别关注异构计算时机,例如量化模型的 GPU/CPU 卸载。例如,我们支持高效的 Llamafile 和Marlin 内核,分别用于 CPU 和 GPU。 更多详细信息可以在这里找到 这里。
示例用法
要使用提供的内核,用户只需创建一个基于 YAML 的注入模板,并在使用 Transformers 模型之前添加对 `optimize_and_load_gguf` 的调用。with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config)
...
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)
在这个示例中,首先在 meta 设备上初始化 AutoModel,以避免占用任何内存资源。然后,optimize_and_load_gguf 遍历模型的所有子模块,匹配您的 YAML 规则文件中指定的规则,并将它们替换为指定的高级模块。
注入后,原始的 generate 接口仍然可用,但我们还提供了一个兼容的 prefill_and_generate 方法,这使得可以进一步优化,例如使用 CUDAGraph 提高生成速度。
如何自定义您的模型
一个详细的使用 DeepSeek-V2 作为示例的注入和 multi-GPU 教程在这里给出 这里。
以下是一个将所有原始 Linear 模块替换为 Marlin 的 YAML 模板示例,Marlin 是一个高级的 4 位量化内核。
- match:
name: "^model\\.layers\\..*$" # 正则表达式
class: torch.nn.Linear # 仅匹配同时符合名称和类的模块
replace:
class: ktransformers.operators.linear.KTransformerLinear # 量化数据类型的优化内核
device: "cpu" # 初始化时加载该模块的 device
kwargs:
generate_device: "cuda"
generate_linear_type: "QuantizedLinearMarlin"
YAML 文件中的每个规则都有两部分:match 和 replace。match 部分指定应替换的模块,replace 部分指定要注入到模型中的模块以及初始化关键字。
您可以在 ktransformers/optimize/optimize_rules 目录中找到用于优化 DeepSeek-V2 和 Qwen2-57B-A14 的示例规则模板。这些模板用于为 local_chat.py 示例提供支持。
If you are interested in our design principles and the implementation of the injection framework, please refer to the design document. 如果您对我们的设计原则和注入框架的实现感兴趣,请参考 设计文档。
致谢和贡献者
KTransformer 的开发基于 Transformers 提供的灵活和多功能框架。我们还受益于 GGUF/GGML、Llamafile 和 Marlin 等高级内核。我们计划通过向上游贡献我们的修改来回馈社区。
KTransformer 由清华大学 MADSys group 小组的成员以及 Approaching.AI 的成员积极维护和开发。我们欢迎新的贡献者加入我们,使 KTransformer 更快、更易于使用。
讨论
如果您有任何问题,欢迎随时提出 issue。或者,您可以加入我们的微信群进行进一步讨论。二维码: 微信群
{kind=link}
🙋 常见问题
一些常见问题的答案可以在 FAQ 中找到。