26 KiB
MiniCPM: Unveiling the Potential of End-side Large Language Models
中文 | English
Technical Blog | Multi-modal Model OmniLMM | CPM-C 100B Model Trial | Join our discord and wechat
MiniCPM is an End-Side LLM developed by ModelBest Inc. and TsinghuaNLP, with only 2.4B parameters excluding embeddings (2.7B in total).
- MiniCPM has very close performance compared with Mistral-7B on open-sourced general benchmarks with better ability on Chinese, Mathematics and Coding after SFT. The overall performance exceeds Llama2-13B, MPT-30B, Falcon-40B, etc.
- After DPO, MiniCPM outperforms Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, Zephyr-7B-alpha, etc. on MTBench.
- MiniCPM-V, based on MiniCPM-2B, achieves the best overall performance among multimodel models of the same scale, surpassing existing multimodal large models built on Phi-2 and achieving performance comparable to or even better than 9.6B Qwen-VL-Chat on some tasks.
- MiniCPM can be deployed and infer on smartphones, and the speed of streaming output is relatively higher than human verbal speed. MiniCPM-V has also successfully deployed multi-modal models on smartphones.
- The cost of developing based on MiniCPM is low. Parameter efficient finetuning can be conducted with a single 1080/2080 GPU and full parameter finetuning can be conducted with a 3090/4090 GPU.
We release all model parameters for research and limited commercial use. In future, we will also release all the checkpoint during training and most public training data for research on model mechanism.
- SFT and DPO version based on MiniCPM-2B and human preference: MiniCPM-2B-SFT/DPO
- The multi-modal model MiniCPM-V based on MiniCPM-2B, which outperforms models with similar size, i.e., Phi-2
- The INT4 quantized version MiniCPM-2B-SFT/DPO-Int4 based on MiniCPM-2B-SFT/DPO
- Mobile phone application based on MLC-LLM and LLMFarm. Both language model and multimodel model can conduct inference on smartphones.
Limitations
- Due to limitations in model size, the model may experience hallucinatory issues. As DPO model tend to generate longer response, hallucinations are more likely to occur. We will also continue to iterate and improve the MiniCPM model.
- To ensure the generality of the model for academic research purposes, we have not subject it to any identity-specific training. Meanwhile, as we use ShareGPT open-source corpus as part of the training data, the model may output identity-related information similar to the GPT series models.
- Due to the limitation of model size, the output of the model is greatly influenced by prompts, which may result in inconsistent results from multiple attempts.
- Due to limited model capacity, the model's knowledge recall may not be accurate. In the future, we will combine the RAG method to enhance the model's knowledge retention ability.
Quick Links
- Updates
- Downloading
- Quick Start
- Community
- Benchmark
- Deployment on Mobile Phones
- Demo & API
- Fine-tuning Models
- LICENSE
- Citation
- Show Cases
Update Log
- 2024/02/13 We support llama.cpp
- 2024/02/09 We have included a Community section in the README to encourage support for MiniCPM from the open-source community.
- 2024/02/08 We updated the llama-format model weights, which can be loaded into LlamaModel directly, making it more convenient for everyone to use our model quickly.
- 2024/02/01 Initial release.
Downloading
-
Language Model
Note:
- The model training was conducted in bf16 format, so inference using bf16 will yield the best results. Other formats might experience a slight performance decline due to precision issues.
- The models with a '-llama-format' suffix are those where we have transformed the MiniCPM structure into the Llama structure (primarily integrating the parameterization scheme of mup into the model's own parameters). This enables users of the Llama model to try out MiniCPM at no extra cost. See details
- Thanks to the contributor for adapting MiniCPM to llama.cpp and ollama.
-
Multimodel Model
HuggingFace ModelScope WiseModel MiniCPM-V MiniCPM-V MiniCPM-V OmniLMM OmniLMM OmniLMM
Quick Start
Online
Huggingface
MiniCPM-2B
- Install
transformers>=4.36.0andaccelerate,run the following python code.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM-2B-dpo-bf16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "Which city is the capital of China?", temperature=0.8, top_p=0.8)
print(responds)
- Examples
The capital city of China is Beijing. Beijing is not only the political center of China but also a cultural and economic hub. It is known for its rich history and numerous landmarks, such as the Great Wall, the Forbidden City, and the Temple of Heaven. The city is also home to the National Stadium, also known as the "Bird's Nest," and the National Aquatics Center, or "Water Cube." Beijing is a significant city in China, with a population of over 21 million people.
MiniCPM-2B (Llama Format)
We have converted the model weights of MiniCPM into a format that can be directly called by Llama code, for everyone to try:
import torch
from transformers import LlamaTokenizerFast, LlamaForCausalLM
model_path = "openbmb/MiniCPM-2B-dpo-bf16-llama-format"
tokenizer = LlamaTokenizerFast.from_pretrained(model_path)
model = LlamaForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
prompt="Now you act like a terminal situated within a beginner's C++ practice repository folder, please provide the output for the command: `ls -l`"
input_ids = tokenizer.encode("<User>{}<AI>".format(prompt), return_tensors='pt', add_special_tokens=True).cuda()
responses = model.generate(input_ids, temperature=0.3, top_p=0.8, repetition_penalty=1.02, max_length=1024)
responses = tokenizer.decode(responses[0], skip_special_tokens=True)
print(responses)
MiniCPM-V
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V', trust_remote_code=True)
model.eval().cuda()
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': question}]
res, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
temperature=0.7
)
print(res)
vLLM
- Install vLLM supporting MiniCPM.
- MiniCPM adopts the MUP program, which introduces some extra scaling operations to make the training process stable. And the MUP structure is a little different from the structure used by Llama and other LLMs.
- vLLM 0.2.2 is adapted to MiniCPM in the folder inference. More vLLM versions will be supported in the future.
pip install inference/vllm
- Transfer Huggingface Transformers repo to vLLM-MiniCPM repo, where
<hf_repo_path>,<vllmcpm_repo_path>are local paths.
python inference/convert_hf_to_vllmcpm.py --load <hf_repo_path> --save <vllmcpm_repo_path>
- Examples
cd inference/vllm/examples/infer_cpm
python inference.py --model_path <vllmcpm_repo_path> --prompt_path prompts/prompt_final.txt
llama.cpp、Ollama、fastllm Inference
We have supported inference with llama.cpp 、ollama、fastllm.
llama.cpp
- install llama.cpp
- download model in gguf format. link-fp16 link-q4km
- In command line:
./main -m ../../model_ckpts/download_from_hf/MiniCPM-2B-dpo-fp16-gguf.gguf --prompt "<用户>Write an acrostic poem with the word MINICPM (One line per letter)<AI>" --temp 0.3 --top-p 0.8 --repeat-penalty 1.05
More parameters adjustment see this
ollama Solving this issue
Community
fastllm
- [install fastllm](fastllm
- inference
import torch
from transformers import AutoTokenizer, LlamaTokenizerFast, AutoModelForCausalLM
path = 'openbmb/MiniCPM-2B-dpo-fp16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float16, device_map='cuda', trust_remote_code=True)
from fastllm_pytools import llm
llm.set_device_map("cpu")
model = llm.from_hf(model, tokenizer, dtype = "float16") # dtype支持 "float16", "int8", "int4"
print(model.response("<用户>Write an acrostic poem with the word MINICPM (One line per letter)<AI>", top_p=0.8, temperature=0.5, repeat_penalty=1.02))
Evaluation results
Evaluation Settings
- Since it is difficult to standardize the evaluation of LLMs and there is no public prompt and test code for a large number of evaluations, we can only try our best to make it suitable for all types of models in terms of specific evaluation methods.
- Overall, we use a unified prompt input for testing, and adjust the input according to the corresponding template for each model.
- The evaluation scripts and prompts have been open-sourced in our Github repository, and we welcome more developers to continuously improve our evaluation methods.
- For the text evaluation part, we use our open source large model capability evaluation framework UltraEval. The following is the open source model reproduction process:
- install UltraEval
git clone https://github.com/OpenBMB/UltraEval.git cd UltraEval pip install -e . - Download the relevant data and unzip it for processing
wget -O RawData.zip "https://cloud.tsinghua.edu.cn/f/71b5232264ae4833a4d0/?dl=1" unzip RawData.zip python data_process.py - Execute evaluation scripts (templates are provided and can be customized)
bash run_eval.sh
- install UltraEval
- For the text evaluation part, we use our open source large model capability evaluation framework UltraEval. The following is the open source model reproduction process:
Deployment mode
- Because MiniCPM uses the structure of Mup, which is slightly different from existing models in terms of specific computations, we have based the implementation of our model on the vllm=0.2.2 version.
- For non-MiniCPM models, we directly sampled the latest version of vllm=0.2.7 for inference.
Evaluation method
- For the QA task (multiple-choice task), we chose to test in two ways:
- PPL: The options are used as a continuation of the question generation and the answer selection is based on the PPL of each option;
- The second is to generate the answer options directly.
- For different models, the results obtained by these two approaches vary widely. the results on both MiniCPM models are closer, while models such as Mistral-7B-v0.1 perform better on PPL and worse on direct generation.
- In the specific evaluation, we take the higher score of the two evaluation methods as the final result, so as to ensure the fairness of the comparison (* in the following table indicates the PPL).
Text evaluation
| Model | Average Score | Average Score in English | Average Score in Chinese | C-Eval | CMMLU | MMLU | HumanEval | MBPP | GSM8K | MATH | BBH | ARC-E | ARC-C | HellaSwag |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B | 35.40 | 36.21 | 31.765 | 32.42 | 31.11 | 44.32 | 12.2 | 27.17 | 13.57 | 1.8 | 33.23 | 75.25 | 42.75 | 75.62* |
| Qwen-7B | 49.46 | 47.19 | 59.655 | 58.96 | 60.35 | 57.65 | 17.07 | 42.15 | 41.24 | 5.34 | 37.75 | 83.42 | 64.76 | 75.32* |
| Deepseek-7B | 39.96 | 39.15 | 43.635 | 42.82 | 44.45 | 47.82 | 20.12 | 41.45 | 15.85 | 1.53 | 33.38 | 74.58* | 42.15* | 75.45* |
| Mistral-7B | 48.97 | 49.96 | 44.54 | 46.12 | 42.96 | 62.69 | 27.44 | 45.2 | 33.13 | 5.0 | 41.06 | 83.92 | 70.73 | 80.43* |
| Llama2-13B | 41.48 | 42.44 | 37.19 | 37.32 | 37.06 | 54.71 | 17.07 | 32.55 | 21.15 | 2.25 | 37.92 | 78.87* | 58.19 | 79.23* |
| MPT-30B | 38.17 | 39.82 | 30.715 | 29.34 | 32.09 | 46.56 | 21.95 | 35.36 | 10.31 | 1.56 | 38.22 | 78.66* | 46.08* | 79.72* |
| Falcon-40B | 43.62 | 44.21 | 40.93 | 40.29 | 41.57 | 53.53 | 24.39 | 36.53 | 22.44 | 1.92 | 36.24 | 81.94* | 57.68 | 83.26* |
| MiniCPM-2B | 52.33 | 52.6 | 51.1 | 51.13 | 51.07 | 53.46 | 50.00 | 47.31 | 53.83 | 10.24 | 36.87 | 85.44 | 68.00 | 68.25 |
| Model | Average Score | Average Score in English | Average Score in Chinese | C-Eval | CMMLU | MMLU | HumanEval | MBPP | GSM8K | MATH | BBH | ARC-E | ARC-C | HellaSwag |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TinyLlama-1.1B | 25.36 | 25.55 | 24.525 | 25.02 | 24.03 | 24.3 | 6.71 | 19.91 | 2.27 | 0.74 | 28.78 | 60.77* | 28.15* | 58.33* |
| Qwen-1.8B | 34.72 | 31.87 | 47.565 | 49.81 | 45.32 | 43.37 | 7.93 | 17.8 | 19.26 | 2.42 | 29.07 | 63.97* | 43.69 | 59.28* |
| Gemini Nano-3B | - | - | - | - | - | - | - | 27.2(report) | 22.8(report) | - | 42.4(report) | - | - | - |
| StableLM-Zephyr-3B | 43.46 | 46.31 | 30.615 | 30.34 | 30.89 | 45.9 | 35.37 | 31.85 | 52.54 | 12.49 | 37.68 | 73.78 | 55.38 | 71.87* |
| Phi-2-2B | 48.84 | 54.41 | 23.775 | 23.37 | 24.18 | 52.66 | 47.56 | 55.04 | 57.16 | 3.5 | 43.39 | 86.11 | 71.25 | 73.07* |
| MiniCPM-2B | 52.33 | 52.6 | 51.1 | 51.13 | 51.07 | 53.46 | 50.00 | 47.31 | 53.83 | 10.24 | 36.87 | 85.44 | 68.00 | 68.25 |
| Model | Average Score | Average Score in English | Average Score in Chinese | C-Eval | CMMLU | MMLU | HumanEval | MBPP | GSM8K | MATH | BBH | ARC-E | ARC-C | HellaSwag |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ChatGLM2-6B | 37.98 | 35.17 | 50.63 | 52.05 | 49.21 | 45.77 | 10.37 | 9.38 | 22.74 | 5.96 | 32.6 | 74.45 | 56.82 | 58.48* |
| Mistral-7B-Instruct-v0.1 | 44.36 | 45.89 | 37.51 | 38.06 | 36.96 | 53.56 | 29.27 | 39.34 | 28.73 | 3.48 | 39.52 | 81.61 | 63.99 | 73.47* |
| Mistral-7B-Instruct-v0.2 | 50.91 | 52.83 | 42.235 | 42.55 | 41.92 | 60.51 | 36.59 | 48.95 | 40.49 | 4.95 | 39.81 | 86.28 | 73.38 | 84.55* |
| Qwen-7B-Chat | 44.93 | 42.05 | 57.9 | 58.57 | 57.23 | 56.03 | 15.85 | 40.52 | 42.23 | 8.3 | 37.34 | 64.44* | 39.25* | 74.52* |
| Yi-6B-Chat | 50.46 | 45.89 | 70.995 | 70.88 | 71.11 | 62.95 | 14.02 | 28.34 | 36.54 | 3.88 | 37.43 | 84.89 | 70.39 | 74.6* |
| Baichuan2-7B-Chat | 44.68 | 42.74 | 53.39 | 53.28 | 53.5 | 53 | 21.34 | 32.32 | 25.25 | 6.32 | 37.46 | 79.63 | 60.15 | 69.23* |
| Deepseek-7B-chat | 49.34 | 49.56 | 48.335 | 46.95 | 49.72 | 51.67 | 40.85 | 48.48 | 48.52 | 4.26 | 35.7 | 76.85 | 63.05 | 76.68* |
| Llama2-7B-Chat | 38.16 | 39.17 | 33.59 | 34.54 | 32.64 | 47.64 | 14.02 | 27.4 | 21.15 | 2.08 | 35.54 | 74.28 | 54.78 | 75.65* |
| MiniCPM-2B | 52.33 | 52.6 | 51.1 | 51.13 | 51.07 | 53.46 | 50.00 | 47.31 | 53.83 | 10.24 | 36.87 | 85.44 | 68.00 | 68.25 |
Multimodal evaluation
| Model | Size | Visual Tokens | MME | MMB dev (en) | MMB dev (zh) | MMMU val | CMMMU val |
|---|---|---|---|---|---|---|---|
| LLaVA-Phi | 3B | 576 | 1335 | 59.8 | - | - | - |
| MobileVLM | 3B | 144 | 1289 | 59.6 | - | - | - |
| Imp-v1 | 3B | 576 | 1434 | 66.5 | - | - | - |
| Qwen-VL-Chat | 9.6B | 256 | 1487 | 60.6 | 56.7 | 35.9 | 30.7 |
| CogVLM | 17.4B | 1225 | 1438 | 63.7 | 53.8 | 32.1 | - |
| MiniCPM-V(3B) | 3B | 64 | 1452 | 67.3 | 61.9 | 34.7 | 32.1 |
DPO evaluation
| Model | MT-bench |
|---|---|
| GPT-4-turbo | 9.32 |
| GPT-3.5-turbo | 8.39 |
| Mistral-8*7b-Instruct-v0.1 | 8.30 |
| Claude-2.1 | 8.18 |
| Zephyr-7B-beta | 7.34 |
| MiniCPM-2B | 7.25 |
| Vicuna-33B | 7.12 |
| Zephyr-7B-alpha | 6.88 |
| LLaMA-2-70B-chat | 6.86 |
| Mistral-7B-Instruct-v0.1 | 6.84 |
| MPT-34B-instruct | 6.39 |
Deployment on mobile phones
Tutorial
- After INT4 quantization, MiniCPM only occupies 2GB of space, meeting the requirements of inference on end devices.
- We have made different adaptations for different operating systems.
- Note: The current open-source framework is still improving its support for mobile phones, and not all chips and operating system versions can successfully run MLC-LLM or LLMFarm.
- Android, HarmonyOS
- Adapt based on open-source framework MLC-LLM.
- Adapted for text model MiniCPM, and multimodel model MiniCPM-V.
- Support MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4、MiniCPM-V.
- Compile and Installation Guide
- iOS
- Adapt based on open-source framework LLMFarm.
- Adapted for text model MiniCPM.
- Support MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4.
- Compile and Installation Guide
Performance
- We did not conduct in-depth optimization and system testing on the mobile inference model, only verifying the feasibility of MiniCPM using mobile phone chips for inference.
- Besides us, there are also some efforts to deploy multimodal models on mobile phones based on llama.cpp. We have verified the feasibility of deploying MiniCPM-V on mobile phones based on MLC-LLM this time, and it can input and output normally. However, there also exist a problem of long image processing time, which needs further optimization :)
- We welcome more developers to continuously improve the inference performance of LLMs on mobile phones and update the test results below.
| Mobile Phones | OS | Processor | Memory(GB) | Inference Throughput(token/s) |
|---|---|---|---|---|
| OPPO Find N3 | Android 13 | snapdragon 8 Gen2 | 12 | 6.5 |
| Samsung S23 Ultra | Android 14 | snapdragon 8 Gen2 | 12 | 6.4 |
| Meizu M182Q | Android 11 | snapdragon 888Plus | 8 | 3.7 |
| Xiaomi 12 Pro | Android 13 | snapdragon 8 Gen1 | 8+3 | 3.7 |
| Xiaomi Redmi K40 | Android 11 | snapdragon 870 | 8 | 3.5 |
| Oneplus LE 2100 | Android 13 | snapdragon 870 | 12 | 3.5 |
| Oneplus HD1900 | Android 11 | snapdragon 865 | 8 | 3.2 |
| Oneplus HD1900 | Android 11 | snapdragon 855 | 8 | 3.0 |
| Oneplus HD1905 | Android 10 | snapdragon 855 | 8 | 3.0 |
| Oneplus HD1900 | Android 11 | snapdragon 855 | 8 | 3.0 |
| Xiaomi MI 8 | Android 9 | snapdragon 845 | 6 | 2.3 |
| Huawei Nova 11SE | HarmonyOS 4.0.0 | snapdragon 778 | 12 | 1.9 |
| Xiaomi MIX 2 | Android 9 | snapdragon 835 | 6 | 1.3 |
| iPhone 15 Pro | iOS 17.2.1 | A16 | 8 | 18.0 |
| iPhone 15 | iOS 17.2.1 | A16 | 6 | 15.0 |
| iPhone 12 Pro | iOS 16.5.1 | A14 | 6 | 5.8 |
| iPhone 12 | iOS 17.2.1 | A14 | 4 | 5.8 |
| iPhone 11 | iOS 16.6 | A13 | 4 | 4.6 |
| Xiaomi Redmi K50 | HyperOS 1.0.2 | MediaTek Dimensity 8100 | 12 | 3.5 |

Demo & API
Web-demo based on Gradio
Using the following command can launch the gradio-based demo.
# generation powered by vllm
python demo/vllm_based_demo.py --model_path <vllmcpm_repo_path>
# generation powered by huggingface
python demo/hf_based_demo.py --model_path <hf_repo_path>
Fine-tuning
-
Parameter-efficient Tuning
- With parameter-efficient tuning, we can tune MiniCPM using one piece of NVIDIA GeForce GTX 1080/2080.
- Code for Parameter-efficient Tuning
-
Full-parameter Tuning
- Using BMTrain,as well as checkpointing and ZeRO-3 (zero redundancy optimizer),we can tune all parameters of MiniCPM using one piece of NVIDIA GeForce GTX 3090/4090.
- This code will be available soon.
Show Cases
Text Generation
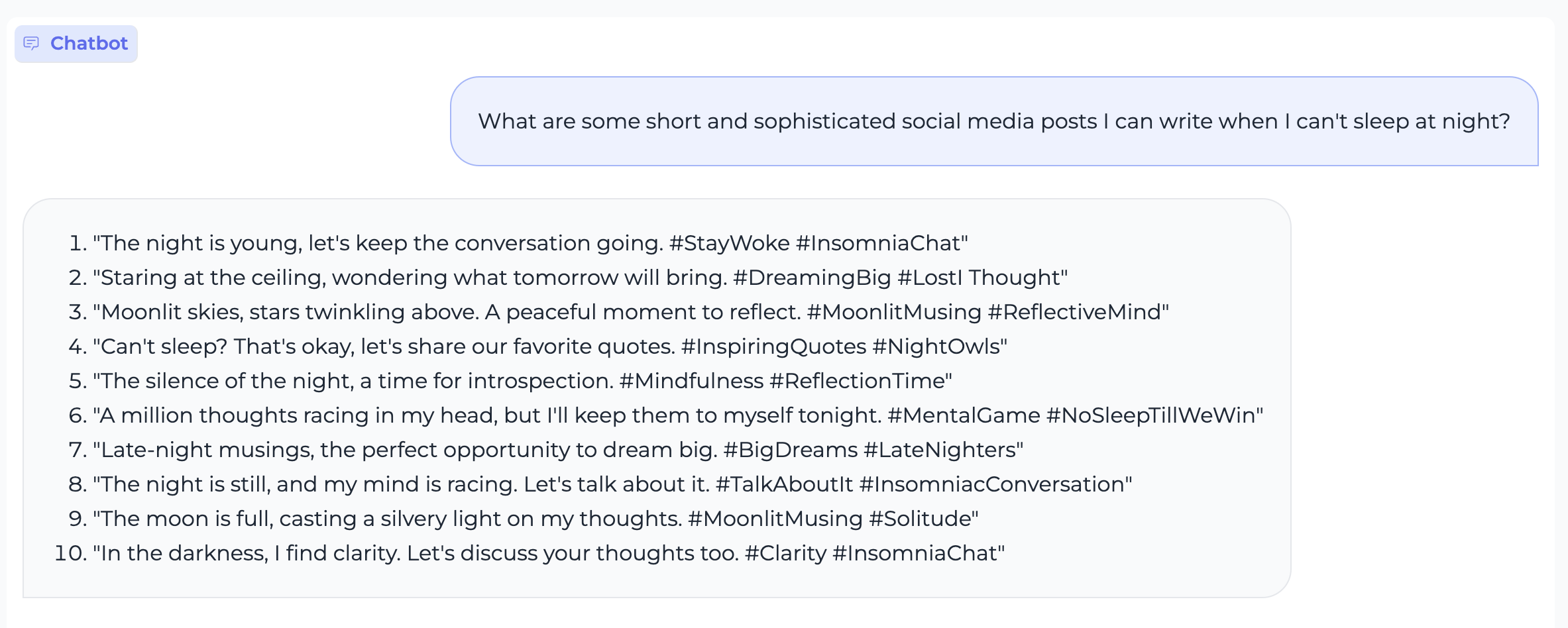
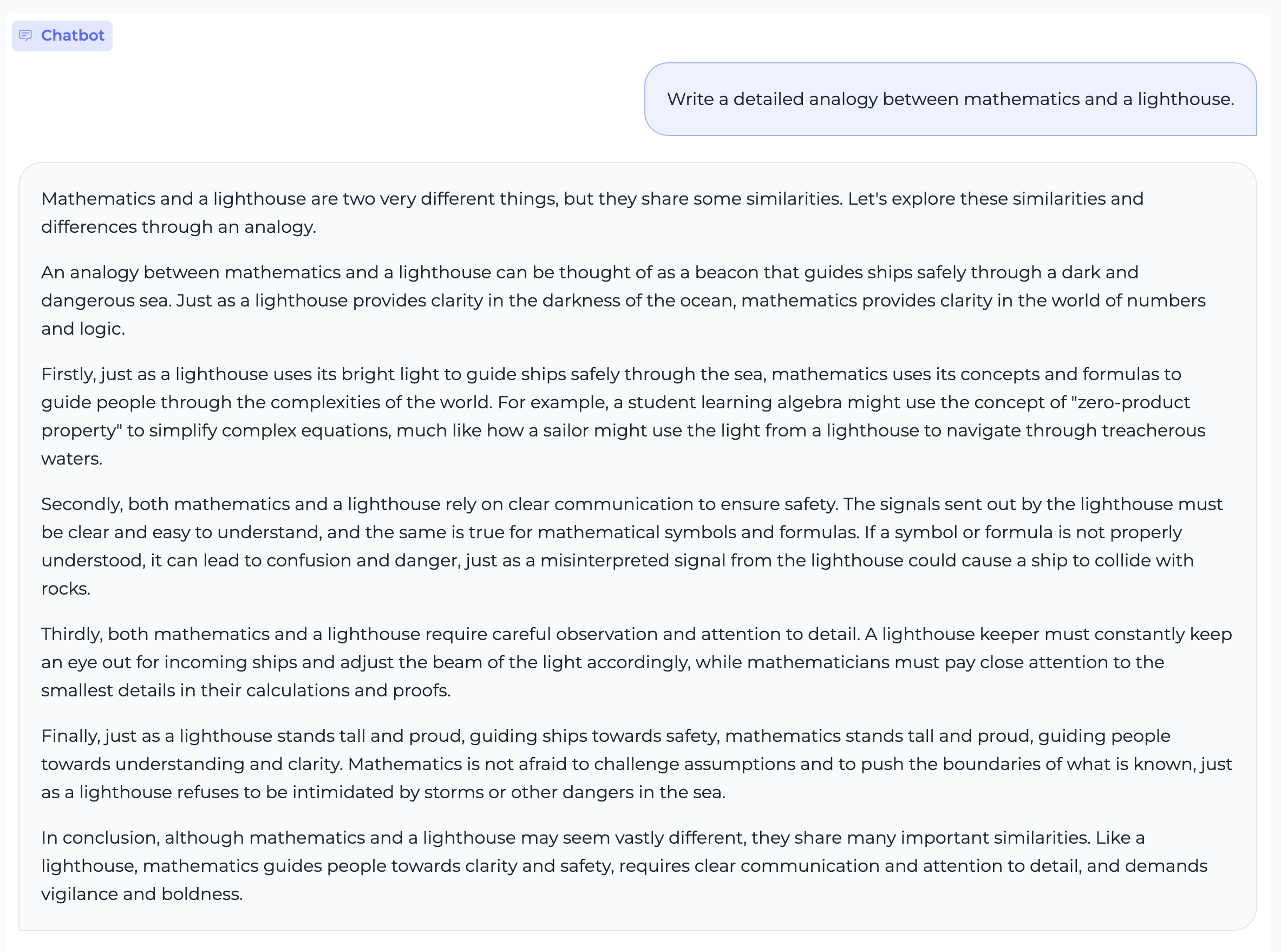
Code Generation

Reasoning
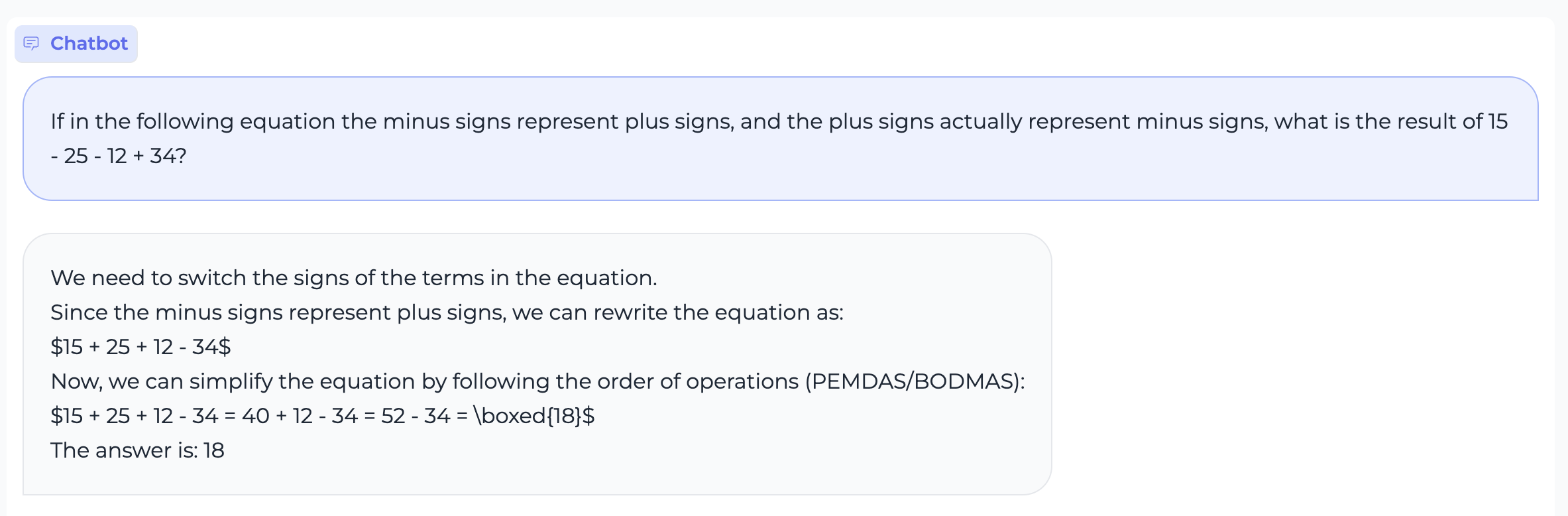
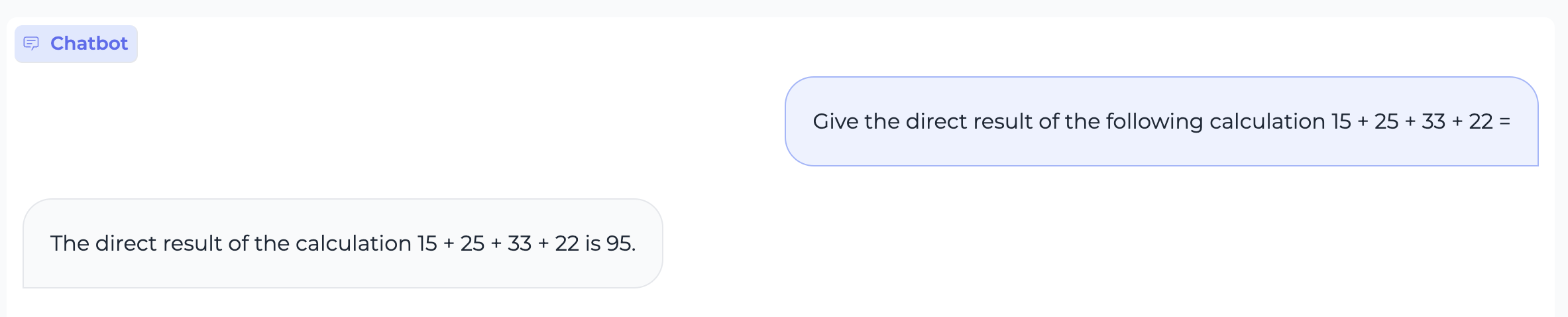
Translation
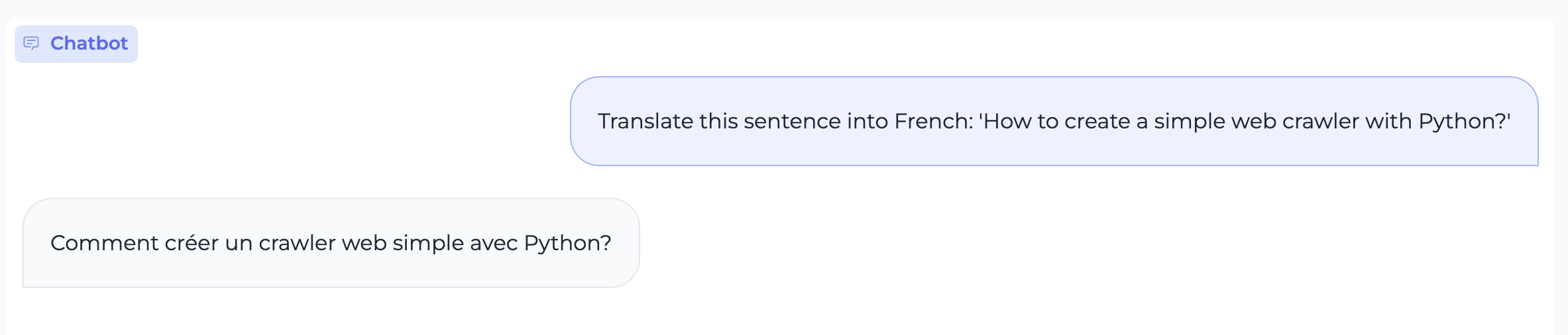
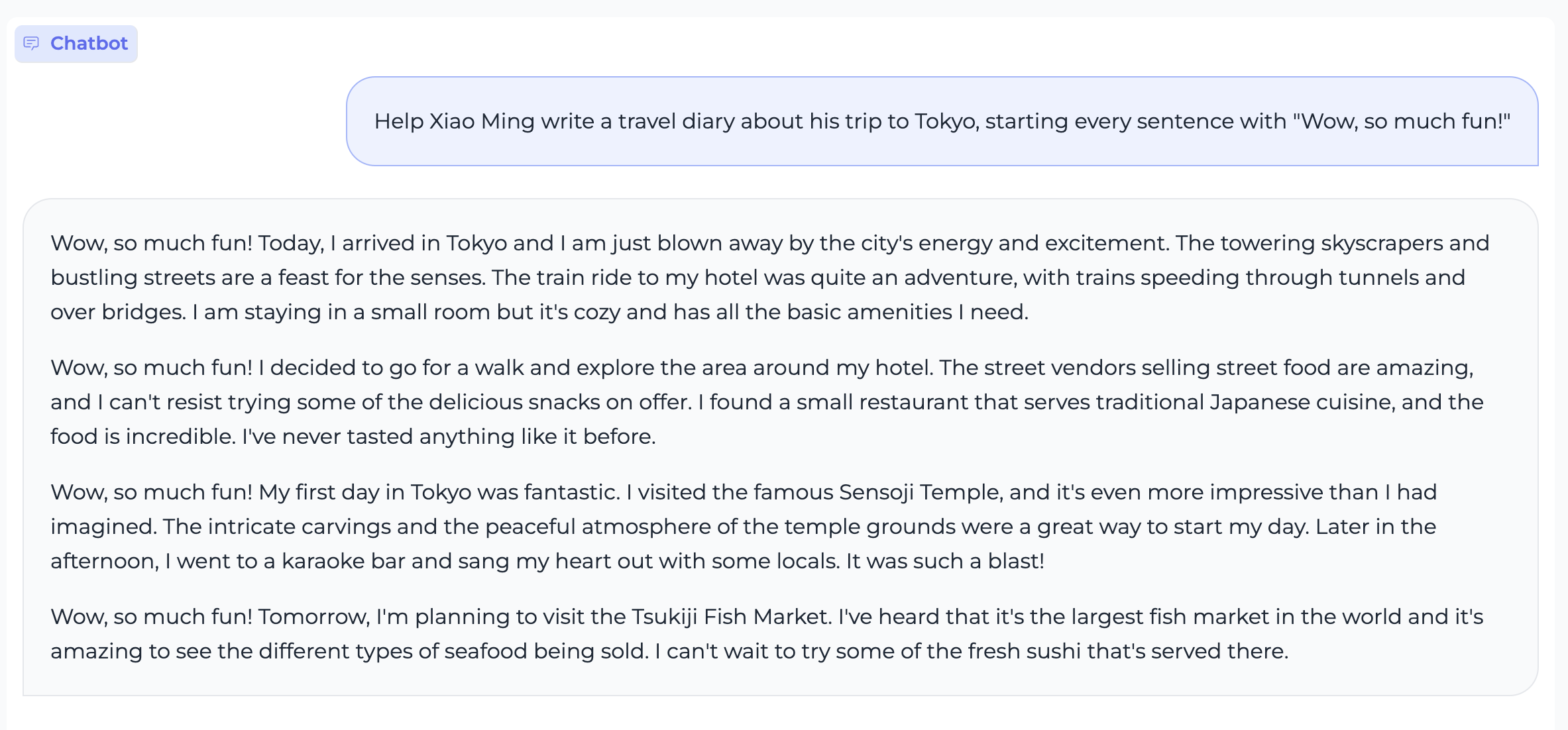
Instruction Following
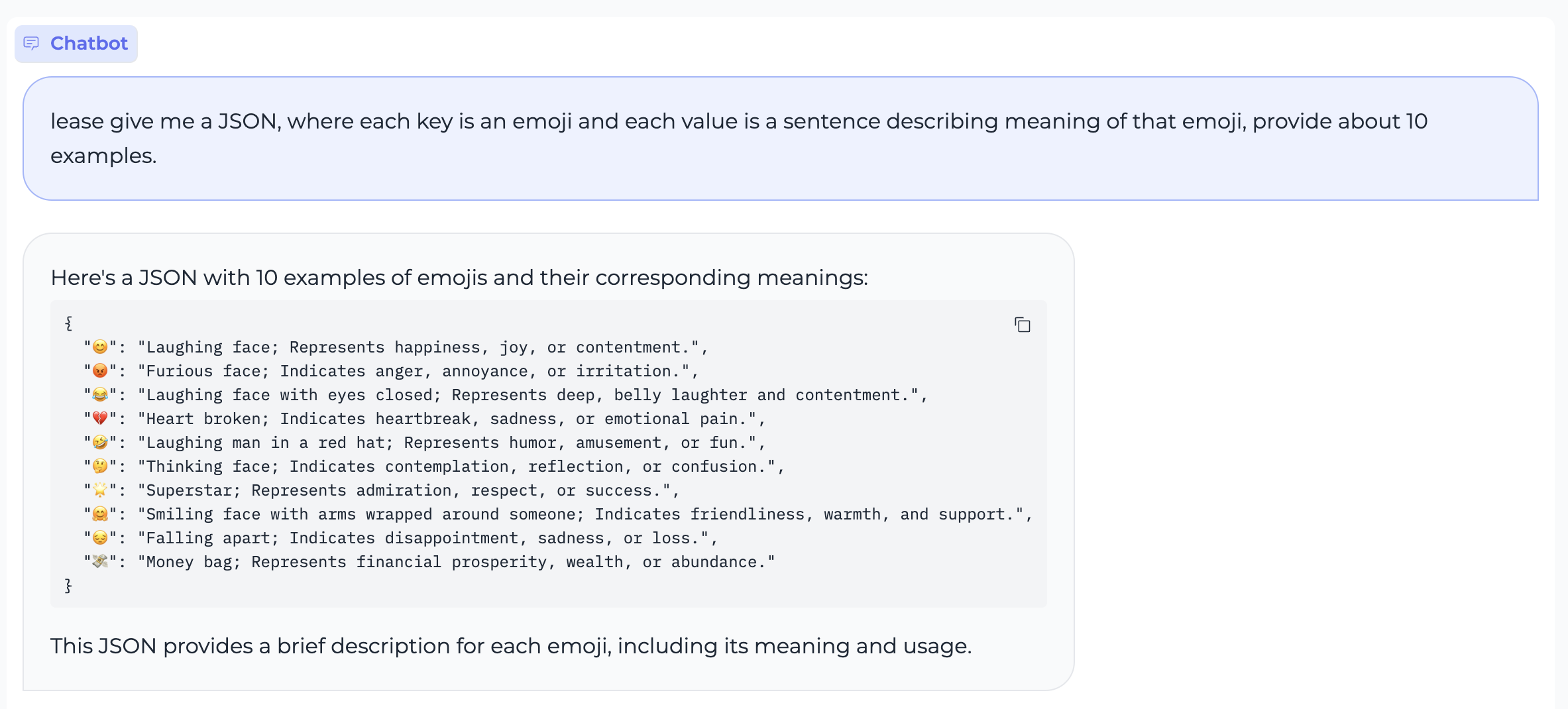
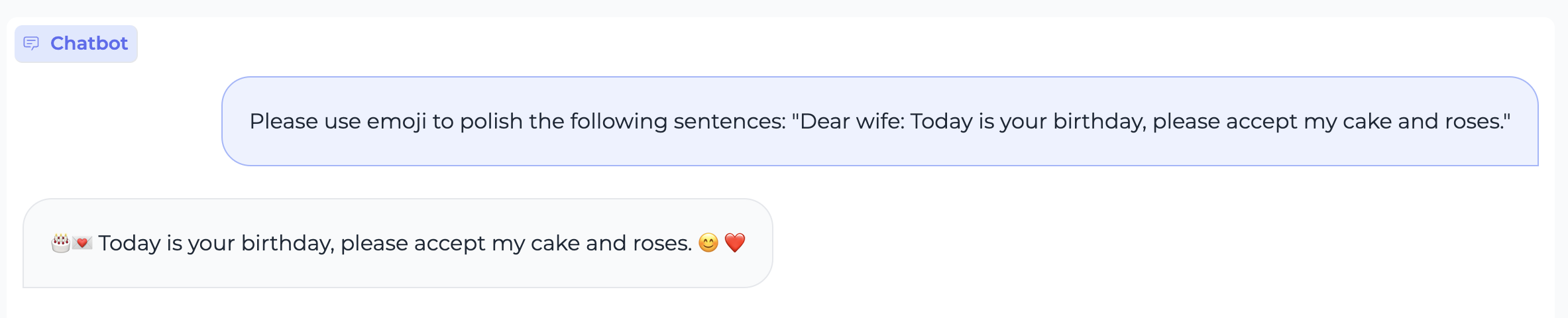
Special characters
LICENSE
Model LICENSE
- This repository is released under the Apache-2.0 License.
- The usage of MiniCPM model weights must strictly follow the General Model License (GML).
- The models and weights of MiniCPM are completely free for academic research.
- If you intend to utilize the model for commercial purposes, please reach out to cpm@modelbest.cn to obtain the certificate of authorization.
Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
Citation
- Please cite our techinical report if you find our work valuable.
@misc{minicpm2024,
title={MiniCPM:Unveiling the Potential of End-side Large Language Models},
booktitle={OpenBMB Blog},
year={2024}
}