中文 | English
Technical Blog |
MiniCPM Wiki (in Chinese) |
MiniCPM Paper |
MiniCPM-V Repo |
Join our discord and WeChat
## Changelog🔥
- [2024.09.05] We release [**MiniCPM3-4B**](https://huggingface.co/openbmb/MiniCPM3-4B)! This model outperforms Phi-3.5-mini-instruct and GPT-3.5-Turbo-0125 and is comparable to several models with 7B-9B parameters like Llama3.1-8B-Instruct, Qwen2-7B-Instruct, and GLM-4-9B-Chat.
- [2024.07.05] Released [MiniCPM-S-1B](https://huggingface.co/openbmb/MiniCPM-S-1B-sft)! This model achieves an average sparsity of 87.89% in the FFN layer, reducing FFN FLOPs by 84%, while maintaining downstream task performance.
- [2024.04.11] Released [MiniCPM-2B-128k](https://huggingface.co/openbmb/MiniCPM-2B-128k), [MiniCPM-MoE-8x2B](https://huggingface.co/openbmb/MiniCPM-MoE-8x2B) and [MiniCPM-1B](https://huggingface.co/openbmb/MiniCPM-1B-sft-bf16)! Click [here](https://openbmb.vercel.app/) to read our technical blog.
- [2024.03.16] Intermediate checkpoints of MiniCPM-2B were released [here](https://huggingface.co/openbmb/MiniCPM-2B-history)!
- [2024.02.01] Released [**MiniCPM-2B**](https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16)! This model performs similarly to Mistral-7B on public benchmarks (with better performance in Chinese, math, and code abilities) and overall outperforms models like Llama2-13B, MPT-30B, and Falcon-40B.
## Quick Links
- [Model Downloads](#model-downloads)
- [MiniCPM 3.0](#minicpm-30)
- [Evaluation Results](#evaluation-results)
- [Comprehensive Evaluation](#comprehensive-evaluation)
- [Function Calling](#function-calling)
- [Long Context](#long-context)
- [Inference](#inference)
- [HuggingFace](#huggingface)
- [vLLM](#vllm)
- [llama.cpp](#llamacpp)
- [Fine-Tuning](#fine-tuning)
- [LLaMA-Factory](#llama-factory)
- [Advanced Features](#advanced-features)
- [Function Calling](#function-calling-1)
- [Code Interpreter](#code-interpreter)
- [MiniCPM 2.0](#minicpm-20)
- [MiniCPM 1.0](#minicpm-10)
## Model Downloads
| HuggingFace | ModelScope |
|-------------|------------|
|[MiniCPM3-4B](https://huggingface.co/openbmb/MiniCPM3-4B)|[MiniCPM3-4B](https://www.modelscope.cn/models/OpenBMB/MiniCPM3-4B)|
|[MiniCPM-2B-sft](https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16)|[MiniCPM-2B-sft](https://modelscope.cn/models/OpenBMB/miniCPM-bf16)|
|[MiniCPM-2B-dpo](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16)|[MiniCPM-2B-dpo](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-bf16/summary)|
|[MiniCPM-2B-128k](https://huggingface.co/openbmb/MiniCPM-2B-128k) |[MiniCPM-2B-128k](https://modelscope.cn/models/openbmb/MiniCPM-2B-128k/summary)|
|[MiniCPM-MoE-8x2B](https://huggingface.co/openbmb/MiniCPM-MoE-8x2B) |[MiniCPM-MoE-8x2B](https://modelscope.cn/models/OpenBMB/MiniCPM-MoE-8x2B)|
|[MiniCPM-1B](https://huggingface.co/openbmb/MiniCPM-1B-sft-bf16) | [MiniCPM-1B](https://modelscope.cn/models/OpenBMB/MiniCPM-1B-sft-bf16) |
|[MiniCPM-S-1B](https://huggingface.co/openbmb/MiniCPM-S-1B-sft)|[MiniCPM-S-1B](https://modelscope.cn/models/OpenBMB/MiniCPM-S-1B-sft)|
Note: More model versions can be found [here](https://huggingface.co/collections/openbmb/minicpm-2b-65d48bf958302b9fd25b698f).
## MiniCPM 3.0
MiniCPM 3.0 is a language model with 4 billion parameters. Compared to MiniCPM 1.0/2.0, it offers more comprehensive features and a significant improvement in overall capabilities. Its performance on most evaluation benchmarks rivals or even surpasses many models with 7B-9B parameters.
* **Supports Function Call🛠️ and Code Interpreter💻**: Achieved SOTA among models with fewer than 9B parameters on the [Berkeley Function Calling Leaderboard (BFCL)](https://gorilla.cs.berkeley.edu/leaderboard.html), outperforming GLM-4-9B-Chat and Qwen2-7B-Instruct.
* **Exceptional Reasoning Ability🧮**: In terms of math abilities, it outperforms GPT-3.5-Turbo and several 7B-9B models on [MathBench](https://open-compass.github.io/MathBench/). On the highly challenging [LiveCodeBench](https://livecodebench.github.io/), it surpasses Llama3.1-8B-Instruct.
* **Outstanding Instruction-Following in English and Chinese🤖**: Exceeds GLM-4-9B-Chat and Qwen2-7B-Instruct on English instruction following with [IFEval](https://huggingface.co/datasets/google/IFEval) and on Chinese instruction following with [FollowBench-zh](https://huggingface.co/datasets/YuxinJiang/FollowBench).
* **Long Context Capability**: Natively supports 32k context length, with flawless performance. We introduce the **LLM x MapReduce** approach, theoretically enabling processing of context lengths up to infinity.
* **RAG Capability**:We release [MiniCPM RAG Suite](https://huggingface.co/collections/openbmb/minicpm-rag-suite-66d976b4204cd0a4f8beaabb). Based on the MiniCPM series models, [MiniCPM-Embedding](https://huggingface.co/openbmb/MiniCPM-Embedding) and [MiniCPM-Reranker](https://huggingface.co/openbmb/MiniCPM-Reranker) achieve SOTA performance on Chinese and Chinese-English cross-lingual retrieval tests. Specifically designed for the RAG scenario, [MiniCPM3-RAG-LoRA](https://huggingface.co/openbmb/MiniCPM3-RAG-LoRA) outperforms models like Llama3-8B and Baichuan2-13B on multiple tasks, such as open-domain question answering.
## Evaluation Results
### Comprehensive Evaluation
| Benchmarks |
Qwen2-7B-Instruct |
GLM-4-9B-Chat |
Gemma2-9B-it |
Llama3.1-8B-Instruct |
GPT-3.5-Turbo-0125 |
Phi-3.5-mini-Instruct(3.8B) |
MiniCPM3-4B |
| English |
| MMLU |
70.5 |
72.4 |
72.6 |
69.4 |
69.2 |
68.4 |
67.2 |
| BBH |
64.9 |
76.3 |
65.2 |
67.8 |
70.3 |
68.6 |
70.2 |
| MT-Bench |
8.41 |
8.35 |
7.88 |
8.28 |
8.17 |
8.60 |
8.41 |
| IFEVAL (Prompt Strict-Acc.) |
51.0 |
64.5 |
71.9 |
71.5 |
58.8 |
49.4 |
68.4 |
| Chinese |
| CMMLU |
80.9 |
71.5 |
59.5 |
55.8 |
54.5 |
46.9 |
73.3 |
| CEVAL |
77.2 |
75.6 |
56.7 |
55.2 |
52.8 |
46.1 |
73.6 |
| AlignBench v1.1 |
7.10 |
6.61 |
7.10 |
5.68 |
5.82 |
5.73 |
6.74 |
| FollowBench-zh (SSR) |
63.0 |
56.4 |
57.0 |
50.6 |
64.6 |
58.1 |
66.8 |
| Mathematics |
| MATH |
49.6 |
50.6 |
46.0 |
51.9 |
41.8 |
46.4 |
46.6 |
| GSM8K |
82.3 |
79.6 |
79.7 |
84.5 |
76.4 |
82.7 |
81.1 |
| MathBench |
63.4 |
59.4 |
45.8 |
54.3 |
48.9 |
54.9 |
65.6 |
| Coding |
| HumanEval+ |
70.1 |
67.1 |
61.6 |
62.8 |
66.5 |
68.9 |
68.3 |
| MBPP+ |
57.1 |
62.2 |
64.3 |
55.3 |
71.4 |
55.8 |
63.2 |
| LiveCodeBench v3 |
22.2 |
20.2 |
19.2 |
20.4 |
24.0 |
19.6 |
22.6 |
| Tool Use |
| BFCL v2 |
71.6 |
70.1 |
19.2 |
73.3 |
75.4 |
48.4 |
76.0 |
| Overall |
| Average |
65.3 |
65.0 |
57.9 |
60.8 |
61.0 |
57.2 |
66.3 |
#### Function Calling
We evaluate the function calling capability of MiniCPM3 on [Berkeley Function Calling Leaderboard (BFCL)](https://gorilla.cs.berkeley.edu/leaderboard.html). MiniCPM3-4B outperforms several models with 7B-9B parameters on this leaderboard, surpassing GPT-3.5-Turbo-0125.
| Model |
Overall Accuracy |
AST Summary |
Exec Summary |
Irrelevance Detection |
Relevance Detection |
| MiniCPM3-4B |
76.03% |
68.55% |
85.54% |
53.71% |
90.24% |
| Llama3.1-8B-Instruct |
73.28% |
64.61% |
86.48% |
43.12% |
85.37% |
| Qwen2-7B-Instruct |
71.61% |
65.71% |
79.57% |
44.70% |
90.24% |
| GLM-4-9B-Chat |
70.08% |
60.69% |
80.02% |
55.02% |
82.93% |
| Phi-3.5-mini-instruct |
48.44% |
38.89% |
54.04% |
46.78% |
65.85% |
| Gemma2-9B-it |
19.18% |
5.41% |
18.50% |
88.88% |
7.32% |
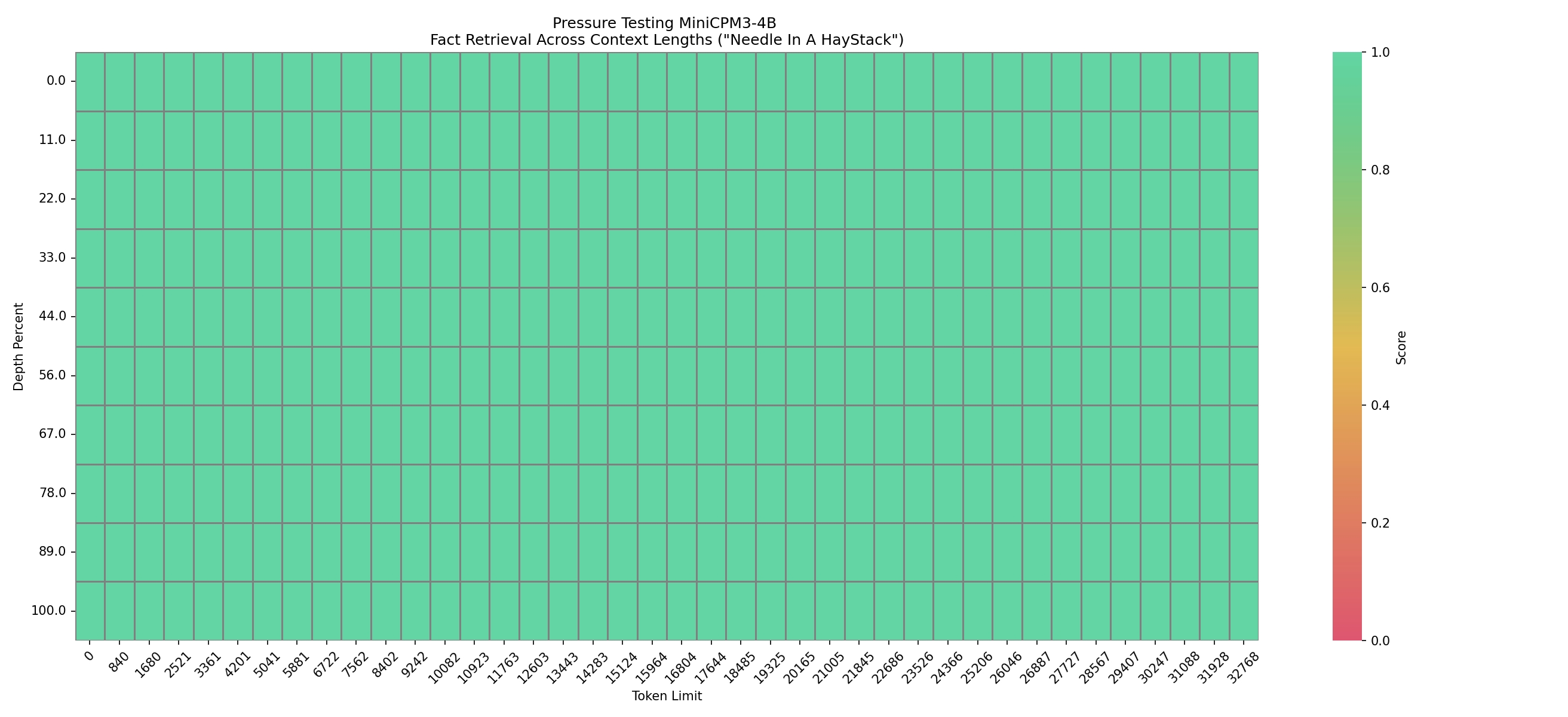
#### Long Context Capability
In the [Needle in a Haystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack) test with a context length of 32k, the results are shown as follows:
### Inference
#### Huggingface
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM3-4B'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "Write an article about Artificial Intelligence.", temperature=0.7, top_p=0.7)
print(responds)
```
#### vLLM
* Install vllm
```shell
pip install git+https://github.com/OpenBMB/vllm.git@minicpm3
```
* Inference
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
model_name = "openbmb/MiniCPM3-4B"
prompt = [{"role": "user", "content": "Write an article about Artificial Intelligence."}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
llm = LLM(model=model_name,
trust_remote_code=True,
tensor_parallel_size=1
)
sampling_params = SamplingParams(top_p=0.7, temperature=0.7, max_tokens=1024)
outputs = llm.generate(prompts=input_text, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
#### llama.cpp
* Install llama.cpp
```shell
git clone https://github.com/OpenBMB/llama.cpp.git
git checkout minicpm3
cd llama.cpp
make
```
* Create model directory
```shell
cd llama.cpp/models
mkdir Minicpm3
```
* Download MiniCPM3 into `llama.cpp/models/Minicpm3`
```shell
cd llama.cpp/models/Minicpm3
git clone https://huggingface.co/openbmb/MiniCPM3-4B
```
* Convert the model to gguf format,and quantize it:
```python
python3 -m pip install -r requirements.txt
python3 convert-hf-to-gguf.py models/Minicpm3/ --outfile /your/path/llama.cpp/models/Minicpm3/CPM-4B-F16.gguf
./llama-quantize ./models/Minicpm3/CPM-4B-F16.gguf ./models/Minicpm3/ggml-model-Q4_K_M.gguf Q4_K_M
```
* Inference
```shell
./llama-cli -c 1024 -m ./models/Minicpm/ggml-model-Q4_K_M.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "<|im_start|>user\nWrite an article about Artificial Intelligence.<|im_end|>\n<|im_start|>assistant\n"
```
### Fine-Tuning
#### LLaMA-Factory
We have supported fine-tuning MiniCPM3 using [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory). For usage instructions, refer to [LLaMA-Factory Fine-tuning](https://modelbest.feishu.cn/docx/Z7USdW4lloZzkZxQ14icJ3senjb?from=from_copylink)."
### Advanced Features
We recommend using [vLLM](#vllm) for the following advanced features.
#### Function calling
We provide example code for using function calls with MiniCPM3:
```bash
cd demo/function_call
python function_call.py
```
If you want to start a function call service, use the following commands:
```bash
cd demo/function_call
pip install -r requirements.txt
python openai_api_server.py \
--model openbmb/MiniCPM3-4B \
--served-model-name MiniCPM3-4B \
--chat-template chatml.jinja \
--dtype auto \
--api-key token-abc123 \
--tensor-parallel-size 1 \
--trust-remote-code
```
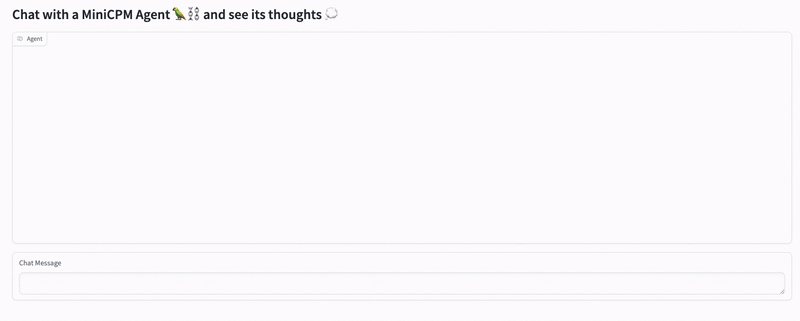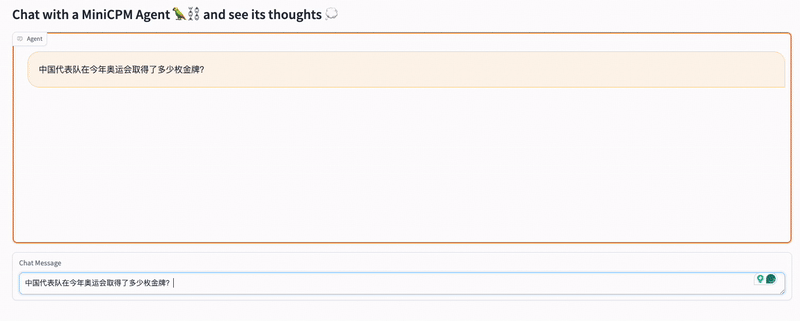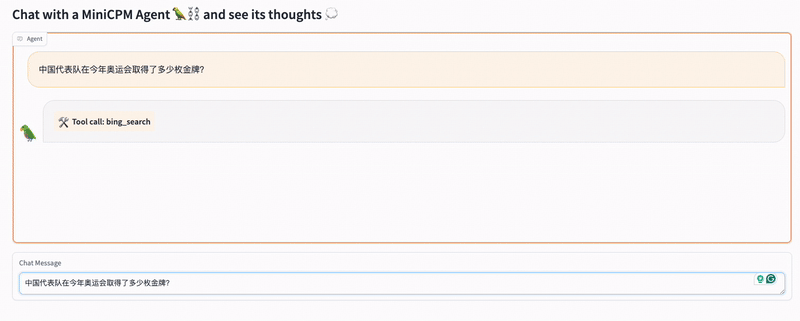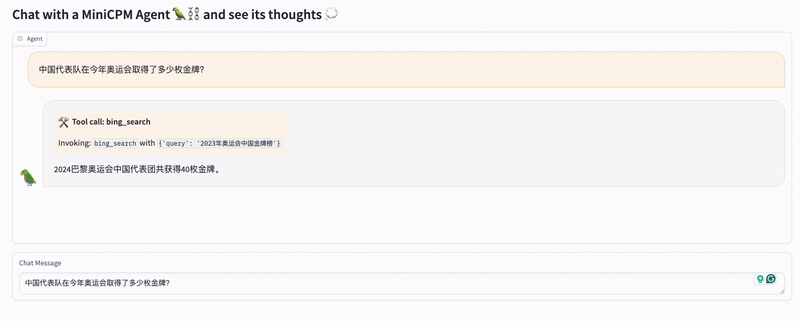
Below is a demo of using a search engine to answer the question:
#### Code Interpreter
We provide example code for using the code interpreter with MiniCPM3:
```bash
cd demo/code_interpreter
pip install -r requirements.txt
python code_interpreter.py openbmb/MiniCPM3-4B
```
Below is an example of using the code interpreter to generate a QR code:

## MiniCPM 2.0
Click to view details about MiniCPM2.0
### Introdution
MiniCPM 2.0 series upgrade MiniCPM in multiple dimensions, including:
- [MiniCPM-2B-128k](https://huggingface.co/openbmb/MiniCPM-2B-128k):Extend the length of MiniCPM-2B context window to 128k, outperform larger models such as ChatGLM3-6B-128k、Yi-6B-200k on InfiniteBench.
- [MiniCPM-MoE-8x2B](https://huggingface.co/openbmb/MiniCPM-MoE-8x2B):Upcycling from MiniCPM-2B. Compared to MiniCPM-2B, the overall performance improves by an average of 4.5pp.
- [MiniCPM-1B](https://huggingface.co/openbmb/MiniCPM-1B-sft-bf16): 60% inference cost reduction compared with MiniCPM-2B, while still showing better overall performance than LLaMA2-13B.
- [MiniCPM-S-1B](https://huggingface.co/openbmb/MiniCPM-S-1B-sft): The FFN layer achieves an average sparsity of 87.89% and reduces FFN FLOPs by 84%, while maintaining no performance loss in downstream tasks. Combined with the PowerInfer, MiniCPM-S-1B inferece speed increase is approximately 2.8x.
### Evaluation Results
#### MiniCPM-2B-128k
| Model | avg | avg w/o code&math | passkey | number_string | kv_retrieval | longbook_choice_eng | longbook_qa_chn | longbook_qa_eng | longbook_sum_eng | longdialogue_qa_eng | math_calc | math_find | code_debug | code_run |
|-------------------------------------|-------|-------------------|---------|---------------|--------------|---------------------|-----------------|-----------------|------------------|---------------------|-----------|-----------|------------|----------|
| LWM-Text-128k | 24.45 | 33.62 | 100 | 97.8 | 0.6 | 28.82 | 15.93 | 14.31 | 9.99 | 1.5 | 0 | 3.43 | 20.05 | 1 |
| Yarn-Mistral-7b-128k | 19.84 | 27.36 | 92.71 | | 0 | 27.95 | 15.49 | 9.55 | 9.06 | 7.5 | 0 | 17.14 | 0.76 | 1.25 |
| Mistral-7B-Instruct-v0.2(ABF 1000w) | 27.75 | 36.9 | 100 | 78.98 | 3.6 | 37.12 | 11.74 | 17.37 | 21.12 | 9.5 | 0 | 29.43 | 17.51 | 0 |
| Yi-6B-200k | 22.15 | 32.54 | 100 | 94.92 | 0 | 36.68 | 15.07 | 9.2 | 0.92 | 3.5 | 0 | 4.29 | 0.51 | 0.75 |
| chatglm3-6b-128k | 25.58 | 36.57 | 89.93 | 99.66 | 5.2 | 46.29 | 10.7 | 8.38 | 25.91 | 6.5 | 0 | 8 | 5.33 | 1 |
| MiniCPM-2.4B-128k | 27.32 | 37.68 | 98.31 | 99.83 | 9 | 29.69 | 23.06 | 16.33 | 15.73 | 9.5 | 0 | 4.29 | 22.08 | 0 |
#### MiniCPM-MoE-8x2B
| Model |
BBH |
MMLU |
CEval |
CMMLU |
HumanEval |
MBPP† |
GSM8K |
MATH |
| Llama2-34B* |
44.1 |
62.6 |
- |
- |
22.6 |
33.0 |
42.2 |
6.24 |
| Mistral-7B-Instruct-v0.2 |
39.81 |
60.51 |
42.55 |
41.92 |
36.59 |
39.63 |
40.49 |
4.95 |
| Gemma-7B* |
55.1 |
64.3 |
- |
- |
32.3 |
44.4 |
46.4 |
24.3 |
| Qwen1.5-7B* |
40.2 |
61 |
74.1 |
73.1 |
36 |
37.4 |
62.5 |
20.3 |
| Deepseek-MoE(16B)* |
- |
45.0 |
40.6 |
42.5 |
26.8 |
39.2 |
18.8 |
4.3 |
| MiniCPM-2.4B |
36.87 |
53.46 |
51.13 |
51.07 |
50.00 |
35.93 |
53.83 |
10.24 |
| MiniCPM-MoE-8x2B |
39.22 |
58.90 |
58.11 |
58.80 |
55.49 |
41.68 |
61.56 |
10.52 |
Note:* means evaluation results are directly taken from their technical reports. † means evaluation results on the full set of
MBPP, instead of the hand-verified set.
#### MiniCPM-S-1B
- Code Generation:Average pass@1 score of HumanEval(0-shot) and MBPP(3-shot).
- Commonsense Reasoning: Average 0-shot accuracy of PIQA, SIQA, HellaSwag, WinoGrande and COPA.
- Reading Comprehension: Average 0-shot accuracy of BoolQ, LAMBADA and TyDi-QA.
- Other Benchmarks: We report average performance of GSM8K(8-shot)、MMLU(5-shot)、BBH(3-shot) and AGI-Eval(0-shot).
| Setting | Average
Sparsity | Average
Performance | Code
Generation | Commonsense
Reasoning | Reading
Comprehension | GSM8K | MMLU | BBH | AGI-Eval |
| :-------------------: | :----------------: | :----------------------: | :----------------------: | :---: | :---: | :---: | :---------: | :-----: | :-----------------: |
| LLaMA2-7B | - | 37.96 | 16.37 | 69.59 | 61.87 | 12.96 | 44.45 | 32.96 | 27.53 |
| ReluLLaMA-7B | 66.98 | 37.62 | 15.85 | 69.64 | 70.54 | 5.84 | 38.64 | 35.07 | 27.73 |
| **ProSparse-7B**\* | 88.11 | 38.31 | 19.47 | 66.29 | 63.33 | 12.74 | 45.21 | 33.59 | 27.55 |
| **ProSparse-7B** | **89.32** | **38.46** | 19.42 | 66.27 | 63.50 | 12.13 | 45.48 | 34.99 | 27.46 |
| LLaMA2-13B | - | 44.06 | 20.19 | 72.58 | 71.55 | 22.21 | 54.69 | 37.89 | 29.33 |
| ReluLLaMA-13B | 71.56 | 42.74 | 20.19 | 70.44 | 73.29 | 18.50 | 50.58 | 37.97 | 28.22 |
| **ProSparse-13B**\* | 87.97 | **45.07** | 29.03 | 69.75 | 67.54 | 25.40 | 54.78 | 40.20 | 28.76 |
| **ProSparse-13B** | **88.80** | 44.90 | 28.42 | 69.76 | 66.91 | 26.31 | 54.35 | 39.90 | 28.67 |
| MiniCPM-1B | - | 44.44 | 36.85 | 63.67 | 60.90 | 35.48 | 50.44 | 35.03 | 28.71 |
| **MiniCPM-S-1B**\* | 86.25 | **44.72** | 41.38 | 64.55 | 60.69 | 34.72 | 49.36 | 34.04 | 28.27 |
| **MiniCPM-S-1B** | **87.89** | **44.72** | 42.04 | 64.37 | 60.73 | 34.57 | 49.51 | 34.08 | 27.77 |
Note:
1. [ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) and [ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B). "ProSparse-7B\*"、"ProSparse-13B\*" and "MiniCPM-S-1B\*" represent ProSparse versions that don't have activation thresholds offset.
2. For PIQA, SIQA, HellaSwag, WinoGrande, COPA, BoolQ, LAMBADA, TyDi QA and AGI-Eval, we adopt ppl-based evalution. For GSM8K, MMLU and BBH, we perform generation-based evalution.
### Inference
#### HuggingFace, vLLM
Please refer to [Inference](#huggingface-inferene) section in MiniCPM1.0.
#### PowerInfer
Currently, PowerInfer is exclusively tailored for the MiniCPM-S-1B model; support for other versions is not yet available, stay tuned.
1. Ensure your cmake version is 3.17 or above. If you have already installed it, you can skip this step.
```bash
# Download the installation package
sudo wget https://cmake.org/files/v3.23/cmake-3.23.0.tar.gz
# Extract the installation package
sudo tar -zxvf cmake-3.23.0.tar.gz
# Configure the installation environment
sudo ./configure
sudo make -j8
# Compile and install
sudo make install
# Check the version after installation
cmake --version
# If the version number is returned, the installation was successful
# cmake version 3.23.0
```
2. Install PowerInfer::
```bash
git clone https://github.com/SJTU-IPADS/PowerInfer
cd PowerInfer
pip install -r requirements.txt # install Python helpers' dependencies
```
3. Compile the CPU version of PowerInfer. If your machine only has a CPU, or if you want to perform inference using the CPU, run the following commands::
```bash
cmake -S . -B build
cmake --build build --config Release
```
4. Compile the GPU version of PowerInfer. If your machine has a GPU, you can run the following commands:
```bash
cmake -S . -B build -DLLAMA_CUBLAS=ON
cmake --build build --config Release
```
5. Retrieve the sparse model:
```bash
git clone https://huggingface.co/openbmb/MiniCPM-S-1B-sft-gguf/tree/main
#or
git clone https://modelscope.cn/models/OpenBMB/MiniCPM-S-1B-sft-gguf
```
6. Model Inference:
```bash
cd PowerInfer
# Below is the command template. output_token_count refers to the maximum output tokens, thread_num is the number of threads, and prompt is the input prompt text.
#./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt
# Below is an example
./build/bin/main -m /root/ld/ld_model_pretrain/1b-s-minicpm/MiniCPM-S-1B-sft.gguf -n 2048 -t 8 -p 'hello,tell me a story please.'
```
## MiniCPM 1.0
Click to view details about MiniCPM1.0
### Introduction
MiniCPM-2B is a dense language model with only 2.4B parameters excluding embeddings (2.7B in total).
- MiniCPM has very close performance compared with Mistral-7B on open-sourced general benchmarks with better ability on Chinese, Mathematics and Coding after SFT. The overall performance exceeds Llama2-13B, MPT-30B, Falcon-40B, etc.
- After DPO, MiniCPM outperforms Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, Zephyr-7B-alpha, etc. on MTBench.
Note: To ensure the generality of the model for academic research purposes, **we have not subject it to any identity-specific training.** Meanwhile, as we use ShareGPT open-source corpus as part of the training data, the model may output identity-related information similar to the GPT series models.
### Evaluation Results
#### Evaluation Settings
* Since it is difficult to standardize the evaluation of LLMs and there is no public prompt and test code for a large number of evaluations, we can only try our best to make it suitable for all types of models in terms of specific evaluation methods.
* Overall, we use a unified prompt input for testing, and adjust the input according to the corresponding template for each model.
* **The evaluation scripts and prompts have been open-sourced in our Github repository, and we welcome more developers to continuously improve our evaluation methods.**
* For the text evaluation part, we use our open source large model capability evaluation framework [UltraEval](https://github.com/OpenBMB/UltraEval). The following is the open source model reproduction process:
* install UltraEval
```shell
git clone https://github.com/OpenBMB/UltraEval.git
cd UltraEval
pip install -e .
```
* Download the relevant data and unzip it for processing
```shell
wget -O RawData.zip "https://cloud.tsinghua.edu.cn/f/71b5232264ae4833a4d0/?dl=1"
unzip RawData.zip
python data_process.py
```
* Execute evaluation scripts (templates are provided and can be customized)
```shell
bash run_eval.sh
```
#### Deployment mode
* Because MiniCPM uses the structure of Mup, which is slightly different from existing models in terms of specific computations, we have based the implementation of our model on the vllm=0.2.2 version.
* **For non-MiniCPM models, we directly sampled the latest version of vllm=0.2.7 for inference.**
#### Evaluation method
* For the QA task (multiple-choice task), we chose to test in two ways:
* PPL: The options are used as a continuation of the question generation and the answer selection is based on the PPL of each option;
* The second is to generate the answer options directly.
* For different models, the results obtained by these two approaches vary widely. the results on both MiniCPM models are closer, while models such as Mistral-7B-v0.1 perform better on PPL and worse on direct generation.
* In the specific evaluation, we take the higher score of the two evaluation methods as the final result, so as to ensure the fairness of the comparison (* in the following table indicates the PPL).
#### Text evaluation
|Model|Average Score|Average Score in English|Average Score in Chinese|C-Eval|CMMLU|MMLU|HumanEval|MBPP|GSM8K|MATH|BBH|ARC-E|ARC-C|HellaSwag|
|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|
|Llama2-7B|35.40|36.21|31.765|32.42|31.11|44.32|12.2|27.17|13.57|1.8|33.23|75.25|42.75|75.62*|
|Qwen-7B|49.46|47.19|59.655|58.96|60.35|57.65|17.07|42.15|41.24|5.34|37.75|83.42|64.76|75.32*|
|Deepseek-7B|39.96|39.15|43.635|42.82|44.45|47.82|20.12|41.45|15.85|1.53|33.38|74.58*|42.15*|75.45*|
|Mistral-7B|48.97|49.96|44.54|46.12|42.96|62.69|27.44|45.2|33.13|5.0|41.06|83.92|70.73|80.43*|
|Llama2-13B|41.48|42.44|37.19|37.32|37.06|54.71|17.07|32.55|21.15|2.25|37.92|78.87*|58.19|79.23*|
|MPT-30B|38.17|39.82|30.715|29.34|32.09|46.56|21.95|35.36|10.31|1.56|38.22|78.66*|46.08*|79.72*|
|Falcon-40B|43.62|44.21|40.93|40.29|41.57|53.53|24.39|36.53|22.44|1.92|36.24|81.94*|57.68|83.26*|
|MiniCPM-2B|52.33|52.6|51.1|51.13|51.07|53.46|50.00|47.31|53.83|10.24|36.87|85.44|68.00|68.25|
|Model|Average Score|Average Score in English|Average Score in Chinese|C-Eval|CMMLU|MMLU|HumanEval|MBPP|GSM8K|MATH|BBH|ARC-E|ARC-C|HellaSwag|
|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|
|TinyLlama-1.1B|25.36|25.55|24.525|25.02|24.03|24.3|6.71|19.91|2.27|0.74|28.78|60.77*|28.15*|58.33*|Qwen-1.8B|34.72|31.87|47.565|49.81|45.32|43.37|7.93|17.8|19.26|2.42|29.07|63.97*|43.69|59.28*|
|Qwen-1.8B|34.72|31.87|47.565|49.81|45.32|43.37|7.93|17.8|19.26|2.42|29.07|63.97*|43.69|59.28*|
|Gemini Nano-3B|-|-|-|-|-|-|-|27.2(report)|22.8(report)|-|42.4(report)|-|-|-|
|StableLM-Zephyr-3B|43.46|46.31|30.615|30.34|30.89|45.9|35.37|31.85|52.54|12.49|37.68|73.78|55.38|71.87*|
|Phi-2-2B|48.84|54.41|23.775|23.37|24.18|52.66|47.56|55.04|57.16|3.5|43.39|86.11|71.25|73.07*|
|MiniCPM-2B|52.33|52.6|51.1|51.13|51.07|53.46|50.00|47.31|53.83|10.24|36.87|85.44|68.00|68.25|
|Model|Average Score|Average Score in English|Average Score in Chinese|C-Eval|CMMLU|MMLU|HumanEval|MBPP|GSM8K|MATH|BBH|ARC-E|ARC-C|HellaSwag|
|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|
|ChatGLM2-6B|37.98|35.17|50.63|52.05|49.21|45.77|10.37|9.38|22.74|5.96|32.6|74.45|56.82|58.48*|
|Mistral-7B-Instruct-v0.1|44.36|45.89|37.51|38.06|36.96|53.56|29.27|39.34|28.73|3.48|39.52|81.61|63.99|73.47*|
|Mistral-7B-Instruct-v0.2|50.91|52.83|42.235|42.55|41.92|60.51|36.59|48.95|40.49|4.95|39.81|86.28|73.38|84.55*|
|Qwen-7B-Chat|44.93|42.05|57.9|58.57|57.23|56.03|15.85|40.52|42.23|8.3|37.34|64.44*|39.25*|74.52*|
|Yi-6B-Chat|50.46|45.89|70.995|70.88|71.11|62.95|14.02|28.34|36.54|3.88|37.43|84.89|70.39|74.6*|
|Baichuan2-7B-Chat|44.68|42.74|53.39|53.28|53.5|53|21.34|32.32|25.25|6.32|37.46|79.63|60.15|69.23*|
|Deepseek-7B-chat|49.34|49.56|48.335|46.95|49.72|51.67|40.85|48.48|48.52|4.26|35.7|76.85|63.05|76.68*|
|Llama2-7B-Chat|38.16|39.17|33.59|34.54|32.64|47.64|14.02|27.4|21.15|2.08|35.54|74.28|54.78|75.65*|
|MiniCPM-2B|52.33|52.6|51.1|51.13|51.07|53.46|50.00|47.31|53.83|10.24|36.87|85.44|68.00|68.25|
#### DPO evaluation
|Model|MT-bench|
|---|---|
|GPT-4-turbo|9.32|
|GPT-3.5-turbo|8.39|
|Mistral-8*7b-Instruct-v0.1|8.30|
|Claude-2.1|8.18|
|Zephyr-7B-beta|7.34|
|**MiniCPM-2B**|**7.25**|
|Vicuna-33B|7.12|
|Zephyr-7B-alpha|6.88|
|LLaMA-2-70B-chat|6.86|
|Mistral-7B-Instruct-v0.1|6.84|
|MPT-34B-instruct|6.39|
### Quick Start
#### Online
- [Colab](https://colab.research.google.com/drive/1tJcfPyWGWA5HezO7GKLeyeIso0HyOc0l?usp=sharing)
#### Web-demo based on Gradio
Using the following command can launch the gradio-based demo.
```shell
# generation powered by vllm
python demo/vllm_based_demo.py --model_path
# generation powered by huggingface
python demo/hf_based_demo.py --model_path
```
#### Huggingface Inferene
##### MiniCPM-2B
* Install `transformers>=4.36.0` and `accelerate`,run the following python code.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM-2B-dpo-bf16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "Which city is the capital of China?", temperature=0.8, top_p=0.8)
print(responds)
```
* Examples
```shell
The capital city of China is Beijing. Beijing is not only the political center of China but also a cultural and economic hub. It is known for its rich history and numerous landmarks, such as the Great Wall, the Forbidden City, and the Temple of Heaven. The city is also home to the National Stadium, also known as the "Bird's Nest," and the National Aquatics Center, or "Water Cube." Beijing is a significant city in China, with a population of over 21 million people.
```
##### MiniCPM-2B (Llama Format)
To facilitate ease of use, we have converted the model weights of MiniCPM to adapt to the structure of the LLaMA model:
```python
import torch
from transformers import LlamaTokenizerFast, LlamaForCausalLM
model_path = "openbmb/MiniCPM-2B-dpo-bf16-llama-format"
tokenizer = LlamaTokenizerFast.from_pretrained(model_path)
model = LlamaForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
prompt="Now you act like a terminal situated within a beginner's C++ practice repository folder, please provide the output for the command: `ls -l`"
input_ids = tokenizer.encode("{}".format(prompt), return_tensors='pt', add_special_tokens=True).cuda()
responses = model.generate(input_ids, temperature=0.3, top_p=0.8, repetition_penalty=1.02, max_length=1024)
responses = tokenizer.decode(responses[0], skip_special_tokens=True)
print(responses)
```
#### vLLM
* Install [vLLM](https://github.com/vllm-project/vllm)
```shell
pip install "vllm>=0.4.1"
```
* Examples
```shell
python inference/inference_vllm.py --model_path --prompt_path prompts/prompt_demo.txt
```
#### llama.cpp, Ollama, fastllm, mlx_lm Inference
We have supported inference with [llama.cpp](https://github.com/ggerganov/llama.cpp/), [ollama](https://github.com/ollama/ollama), [fastllm](https://github.com/ztxz16/fastllm), [mlx_lm](https://github.com/ml-explore/mlx-examples). Thanks to [@runfuture](https://github.com/runfuture) for the adaptation of llama.cpp and ollama.
Please refer to [Quantization Tutorial](https://modelbest.feishu.cn/wiki/EatbwdLuvitbbMk2X5wcX6h5n7c) in "MiniCPM Knowbase".
#### Parameter-efficient Tuning
* With parameter-efficient tuning, we can tune MiniCPM using one piece of NVIDIA GeForce GTX 1080/2080.
* mlx finetune:[Guideline](https://modelbest.feishu.cn/wiki/AIU3wbREcirOm9kkvd7cxujFnMb#share-ASrDdvFAloHtycxfy85cLNhAnd3)
- [xtuner](https://github.com/InternLM/xtuner): [The best choice to do parameter-efficient tuning on MiniCPM](https://modelbest.feishu.cn/wiki/AIU3wbREcirOm9kkvd7cxujFnMb#AMdXdzz8qoadZhxU4EucELWznzd)
- [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory.git):[One click solution of finetuning MiniCPM](https://modelbest.feishu.cn/wiki/AIU3wbREcirOm9kkvd7cxujFnMb#BAWrdSjXuoFvX4xuIuzc8Amln5E)
## LICENSE
#### Model LICENSE
* This repository is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
* The usage of MiniCPM model weights must strictly follow [MiniCPM Model License](https://github.com/OpenBMB/MiniCPM/blob/main/MiniCPM%20Model%20License.md).
* The models and weights of MiniCPM are completely free for academic research. after filling out a [questionnaire](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, are also available for free commercial use.
#### Statement
* As a language model, MiniCPM generates content by learning from a vast amount of text.
* However, it does not possess the ability to comprehend or express personal opinions or value judgments.
* Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
* Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## Institutions
This project is developed by the following institutions:
-  [Modelbest Inc.](https://modelbest.cn/)
-
[Modelbest Inc.](https://modelbest.cn/)
-  [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
## Citation
* Please cite our [paper](https://arxiv.org/abs/2404.06395) if you find our work valuable.
```
@misc{hu2024minicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Shengding Hu and Yuge Tu and Xu Han and Chaoqun He and Ganqu Cui and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Weilin Zhao and Xinrong Zhang and Zheng Leng Thai and Kaihuo Zhang and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and Dahai Li and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2404.06395},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
## Citation
* Please cite our [paper](https://arxiv.org/abs/2404.06395) if you find our work valuable.
```
@misc{hu2024minicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Shengding Hu and Yuge Tu and Xu Han and Chaoqun He and Ganqu Cui and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Weilin Zhao and Xinrong Zhang and Zheng Leng Thai and Kaihuo Zhang and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and Dahai Li and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2404.06395},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```